

On ne manquera évidemment pas de noter la disparition du suffixe FX. NVIDIA ayant manifestement envie de se débarrasser de l'image relativement négative induite par la famille NV3x. Le NV40 est à ce titre identifié par NVIDIA comme la sixième série de Processeurs GeForce. Il s'agit d'ailleurs d'un produit capital pour la firme de Santa Clara et ce pour deux raisons. Il doit tout d'abord permettre à NVIDIA de retrouver un leadership incontestable sur le marché de la 3D, mais du succès du NV40, va dépendre le succès de toutes ses futures déclinaisons. Il ne faut en effet pas oublier que cette nouvelle architecture NV40 sera à la base de toutes les futures cartes entrée et moyen de gamme de la compagnie.
Techniquement, et sans rentrer dans les détails, le NV40 est un chip graphique DirectX 9.0 de seconde génération. Il a pour difficile mission de succéder aux NV35/38 dont l'architecture avait été particulièrement critiquée. De l'aveu même du CEO de NVIDIA, Jen-Hsun Huang, tout le monde a son lot d'idées stupides mais l'important est d'apprendre de ses erreurs. Si le NV35 était un premier pas dans ce sens, le NV40 est définitivement la réponse de NVIDIA aux critiques qui avaient fusées contre le NV30. La clef de cette possible réussite se cache dans les spécifications hors normes du NV40 et dans son support du Shader Model 3.0 qui officialise le support des shaders en FP32. Il faut bien dire, qu'outre un nombre de pipelines beaucoup trop limité, le GeForce FX 5900 était pénalisé par une puissance de calcul trop faible en Pixel Shaders 2.0 : ce point essentiel pour les jeux de dernière génération a été l'un des axes de développement du GeForce 6800. Cela permettra-t-il à NVIDIA de reconquérir sa couronne, perdue au moment de la sortie du R300 ?


NVIDIA GeForce 6800 : Une toute nouvelle architecture grâce au CineFX 3.0
Avec le GeForce 5800, puis avec son grand frère, NVIDIA avait initié le CineFX un moteur graphique conçu pour délivrer une qualité dite cinématographique. A l'époque NVIDIA mettait en avant la possibilité de traiter les shaders avec une précision de 32 bits. Hélas pour NVIDIA, DirectX 9.0 se bornait à un traitement sur 24 bits handicapant lourdement les GPU du groupe : en travaillant avec leur précision maximale (FP32) ils s'avéraient largement moins performants que ceux de la concurrence. Du coup, NVIDIA a du jongler entre FP16 et FP32 pour que ses chips délivrent des performances satisfaisantes.De fait l'architecture CineFX était franchement peu convaincante et il fallu attendre l'arrivée du CineFX 2.0 pour que NVIDIA rattrape une partie de son retard face à la série R3xx de son éternel rival canadien en augmentant à la fois la puissance de calcul tout en maintenant une qualité de rendu maximale. Le NV40 est pour NVIDIA l'occasion de faire table rase du passé en présentant le CineFX 3.0. Les deux principales fonctionnalités de ce nouveau moteur sont le support du modèle de Shaders 3.0 et du tout frais OpenGL 1.5 par l'entremise des langages HLSL, GLSL ou Cg.
DirectX 9.0c et le Shader Model 3.0
Le Shader Model 3.0 est une évolution logique de la version 2.0 apparue avec DirectX 9.0. Il apporte essentiellement plus de souplesse aux développeurs en faisant tomber un certain nombre de limitations. Le nombre d'instructions maximales d'un shader passe ainsi de 96 à 65535 instructions pour les Pixel Shaders et de 256 à 65535 instructions pour les Vertex Shaders. Autre nouveauté de taille, les Shader Models 3.0 exploitent dorénavant une précision de calcul en FP32. Si les spécifications des Shaders Models 3.0 font état d'un nombre maximal d'instructions, le NV40 n'est pas assujetti à ces contraintes, du moins en théorie. En outre NVIDIA propose en standard le Dynamic FlOw Control qui offre un support complet des sous-routines, branches, boucles et autres codes de condition à la fois pour les Vertex & Pixel Shaders. Cet ensemble de fonctionnalités permet aux développeurs d'avoir un plus grand contrôle sur le fonctionnement de ses shaders.Les Vertex Shaders dans leur version 3.0 continuent d'offrir le support du Displacement mapping, une sorte d'évolution de la technologie Bump Mapping chère à Matrox. Alors qu'ATI propose cette technologie depuis le Radeon 9700, NVIDIA l'adopte enfin. Par rapport au Bump Mapping, le Displacement Mapping, bien que plus coûteux en terme de ressources GPU, offre un plus grand niveau de réalisme grâce à l'emploi des shaders. Pour cela, le moteur CineFX 3.0 permet d'associer les informations de texture aux vertices (autrement dit le sommet d'un triangle) en utilisant un minimum d'instructions ce qui permet d'éliminer la plupart des surfaces lisses. Dans l'exemple donné par NVIDIA, une tête de dinosaure modélisée (voir illustration ci-dessous) arbore des contours parfaitement lisses. L'application du Displacement Mapping transforme la tête en faisant apparaître, en plus d'une texture, des détails bosselés et accidentés qui sont capables de réagir à la lumière. Contrairement au Bump Mapping, le Displacement Mapping donne du relief au lieu de le simuler. Les Vertex Shaders 3.0 introduisent également une meilleure gestion géométrique avec le Vertex Stream Divider qui optimise l'utilisation du bus et du GPU en permettant à un programme de spécifier des fréquences multiples pour la lecture des informations sur les vertex afin, par exemple, d'appliquer le même effet à un ensemble d'objets.

Le displacement mapping en action
Du côté des Pixel Shaders 3.0, le NV40, outre les fonctionnalités précédemment décrites, propose la technologie MRT, pour Multiple Render Targets. Cette fonction permet à un pixel shader de stocker des données sur chacun des pixels dans plusieurs zones tampons. Egalement connue sous le nom de Deferred Shading, le MRT permet d'utiliser les données stockées dans les buffers comme des paramètres pour les réutiliser dans des shaders de lumière. Avec cette approche il devient possible d'appliquer les effets de lumière une fois que la géométrie de la scène a été rendue sans pour autant le faire en plusieurs passes. Cela est particulièrement utile pour le HDR ou High Dynamic Range qui reproduit avec un plus grand réalisme les effets d'éblouissement ou de forte luminosité liés par exemple aux contre-jours, ce que nous verrons plus loin.
Comme à chaque nouvelle évolution de l'API, il faudra bien sûr attendre quelques mois avant de voir apparaître les premiers jeux exploitant les Pixel Shaders 3.0. En fait, l'attente pourrait être moins longue que prévue, puisque Far Cry peut déjà reconnaître les fonctionnalités Pixel Shaders 3.0 à condition de disposer de la bonne version de DirectX et du patch 1.1. Il va falloir en effet patienter jusqu'à ce que Microsoft publie la version 9.0c du runtime DirectX afin que le Shader Model 3.0 soit pleinement supporté et exploitable par nous autres les utilisateurs. En attendant et de par la nature méme de ce Shader Model 3.0, les modes de fonctionnement de l'architecture NV40 restent limités aux FP16 et FP32, le FP24 n'étant toujours pas à l'ordre du jour.


Démos technologiques de NVIDIA : à l'abordage & NALU !
Les pipes, le chip, la mémoire et l'interface

Avec un tel nombre de pipelines, il n'est pas surprenant d'apprendre que le NV40 comporte le nombre record de 222 millions de transistors. Mesurant 40 mm x 40 mm le die de la puce reste fabriqué en 0.13µ par et est cadencé à 400 MHz. Physiquement, le NV40 conserve un packaging de type "flip-chip" mais son die est apparent, alors qu'une sorte de "placer" métallique recouvre les extrémités de la puce. Ce nombre élevé de transistors implique une forte consommation électrique et NVIDIA conseille d'ailleurs de disposer d'une alimentation de 450 Watts minimum, la puce et sa mémoire consommant en théorie entre 100 et 110 Watts ! Dans les faits vous devriez pouvoir vous en sortir avec une alimentation 350 Watts pour peu que votre système ne soit pas trop chargé. Question mémoire, le NV40 dispose d'une interface 256 bits et fait appel à de la GDDR3 cadencée à 1.1 GHz. La mémoire GDDR3 représente une évolution significative de la DDR2, puisque grâce à une plus grande finesse de gravure, les puces sont plus rapides et chauffent moins. Cela se ressent directement sur la bande passante mémoire, le NV40 pouvant délivrer près de 35.2 Go par seconde. Précisons que le GeForce 6800 dispose d'un contrôleur mémoire Crossbar fonctionnant sur quatre voies. Toutefois et malgré une fréquence élevée de 550 MHz, il aurait fallu que la DDR3 tourne à 600 MHz pour que les seize pipes du NV40 soient pleinement exploités. L'architecture a donc encore un certain potentiel d'évolution avec les prochaines montées en puissance tant de la mémoire que de l'interface qui est pour l'instant en AGP 8x.

Le die du NV40
Pour cette première version, le GeForce 6800 Ultra se limite à l'interface AGP 8x, faute de plates-formes PCI-Express disponibles. L'utilisation du bus AGP 8x se fait de manière native, NVIDIA n'ayant pas recours avec le NV40 au fameux bridge (ou HSI), du moins pour le moment. Du coup toutes les fonctionnalités classiques de l'AGP 8x sont supportées comme les fast writes. Il faudra vraisemblablement attendre l'arrivée du NV45 pour que le PCI-Express soit supportée nativement par les GeForce 6 haut de gamme.
Une architecture superscalaire massivement parallèle !
Le NV40 se distingue de ses prédécesseurs grâce à son architecture de type superscalaire. Celle-ci se caractérise par la présence de deux unités de shaders par texturing unit qui permettent d'exécuter un maximum de quatre instructions par cycle soit un total de huit opérations par pixel. Cette architecture superscalaire a toutefois une limite, puisque lorsque le GPU doit traiter à la fois des pixels et des textures, il ne peut alors exécuter que quatre opérations par pixel.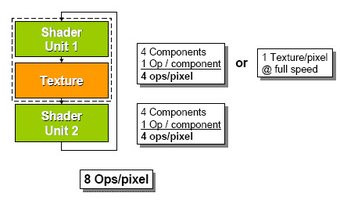
Typiquement les architectures DirectX 9.0 peuvent fonctionner en mode 'Co-Issue' c'est-à-dire exécuter deux instructions indépendantes au sein de la même unité de shaders en mode 3/1 (trois opérations + une opération). Le NV40 redéfinit le fonctionnement Co-Issue en autorisant de plus larges combinaisons avec un fonctionnement 3/1 ou 2/2. Mais grâce à la seconde unité de shaders, NVIDIA parvient à autoriser l'exécution de deux instructions dans le même cycle d'horloge dans les deux unités de shaders et ce aussi bien en mode 3/1 qu'en mode 2/2. Dès lors, le NV40 peut traiter en Dual-Issue quatre instructions par pixel et par cycle contre deux instructions par pixel et par cycle pour le R3xx, ceci dans le but d'augmenter le parallélisme pour des performances toujours plus élevées. Le Dual-Issue permet donc au NV40 d'être plus souple et plus flexible à programmer. Pour avoir une idée tangible du gain de performance induit par le Dual Issue et l'architecture superscalaire, on peut prendre un shader comportant 26 opérations arithmétiques et quatre textures. Un NV35 le traitera en douze passes, alors que le NV40 s'acquittera de cette tâche en seulement six passes... En d'autres termes, cette architecture parallèle permet à chacun des pipelines du NV40 d'exécuter différentes instructions, sur différents jeux de données en même temps.
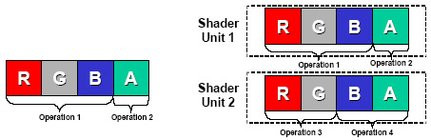
Une des autres avancées de l'architecture NV40 tient à ce que NVIDIA appelle l'Opportunistic Instruction Execution. Il s'agit en fait d'une fonction de prefetching ou de prédicition de branchement en français dans le texte qui permet au processeur de deviner quelles données seront requises par l'étape suivante d'un shader en cours d'exécution. Grâce à cette fonction le processeur précharge les données qu'il estime bientôt nécessaires ce qui permet d'accélérer encore les temps d'exécution et donc les performances des shaders.
De nouvelles technologies pour un réalisme toujours plus poussé : le HDR
Le moteur CineFX 3.0 apporte son lot de nouveautés avec en sus des grands chambardements précédemment évoqués, de nouvelles fonctions pour des effets visuels toujours plus saisissants. Le premier d'entre eux est le High Dynamic Range dont le but est de représenter les lumières violentes avec une plus grande intensité mais aussi avec plus de nuances et de précision. La technologie NVIDIA High Precision Dynamic Range permet de faire l'économie des conversions vers RGBE ou RGBM précédemment nécessaires pour l'application de ce type d'effets. Le GPU décompose pour cela l'application d'un effet HDR en trois étapes avec d'abord le transport de la lumière, puis le mappage de la tonalité avec enfin les corrections colorimétrique et gamma. Utilisant un encodage similaire à celui du standard OpenEXR et basé sur l'équation DR = log10(max_intensity/min_intensity), le NVHPDR calcule le taux de réflexion d'une surface, en prenant en compte les lumières de plusieurs sources, et en appliquant, si besoin est, quelques effets comme des lueurs, de la profondeur ou des effets de flou. La fonction peut également travailler avec des textures en virgule flottante. La palette de perception de l'œil humain en matière d'intensité lumineuse est de 14 dB. Jusqu'alors les effets de type sRGB permettaient d'obtenir au mieux une palette de 5.9 dB alors que la technologie de NVIDIA offre près de 12 dB. Le niveau de contraste d'une scène est donc bien meilleur avec le NVHPDR, ce qui devrait offrir un réalisme des plus convaincant. Notez que NVIDIA utilise ici une fonction longtemps exploitée par les studios de cinéma et déjà disponible sur les cartes ATI, il est vrai sous une autre forme... Les premières générations de Quadro découlant du NV40 devraient donc être encore davantage plébiscitées par les studios de création même si le support du HDR en FP32 semble pour le moment exclus, du moins avec le NV40. Sachez enfin que Half-Life 2 et Medal Of Honor Pacific Assault figurent parmi les jeux qui feront appel aux effets de type HDR, d'où l'importance de la prise en charge de cette fonction par les derniers Processeurs graphiques de NVIDIA.
High Dynamic Range : à gauche un "mauvais" rendu de contre-jour, à droite un rendu utilisant le NVHPDR
NVIDIA UltraShadow II
Avec le GeForce 6, NVIDIA propose également une nouvelle version de sa technologie UltraShadow, l'UltraShadow II (NDLR : que c'est original !) pour une gestion plus poussée des effets d'ombrage. Par rapport à la première version de l'UltraShadow qui remonte au NV35, cette évolution se base surtout sur la puissance brute de calcul du NV40 qui devrait permettre, selon NVIDIA, de quadrupler les performances du GPU pour le calcul des ombrages. Les ingénieurs de Santa-Clara ont bien entendu profité de cette version 2 pour optimiser leur algorithme afin de le rendre encore plus efficace. Rappelons que le principe de l'UltraShadow est, à la manière du Z-Culling, de ne calculer que les ombres qui seront effectivement visibles dans le rendu final d'une scène afin d'économiser un maximum de puissance.
Une scène de Doom III : observez à gauche un rendu complexe des ombres, à droite un rendu simplifié grâce à l'UltraShadow II
Tous à l'ombre !
La firme au caméléon propose également le support du Subsurface scattering pour des effets translucides plus prenants. L'explication technique ne vous avancera guère sur la réalité du Subsurface scattering aussi nous allons prendre un exemple de la vie courante. Tout le monde a déjà pu faire l'expérience suivante : en mettant sa main sous une source lumineuse intense la peau devient partiellement transparente sur les extrémités ou dans les zones dépourvues d'ossements. Le Subsurface scattering permet tout simplement d'obtenir ce genre d'effets dans les jeux avec une pénétration plus ou moins importante de la lumière sur les surfaces. Le prochain Black & White 2 aura recours à cette fonction.
Le Subsurface Scattering
Le GeForce 6800 supporte également les Soft Shadows ou ombres douces : ce type d'ombre tire sa particularité du fait que ses bords, générés par la source lumineuse de la scène, sont adoucis. Le pipeline 32 bit du NV40 permet en outre d'appliquer des effets d'ombres sur diverses surfaces comme l'herbe, la végétation ou la terre et ce sans perte de performance ni anomalie visuelle. Enfin, le fait que le NV40 supporte des Pixel Shaders d'une longueur infinie permet d'envisager la gestion en temps réel des sources lumineuses pour un réalisme toujours plus saisissant.

Des exemples de Soft Shadows
NVIDIA IntelliSample 3.0
L'antialiasing évolue en douceur grâce au NV40. Avec le IntelliSample 3.0, NVIDIA supporte dorénavant le Centroid Sampling qui est une fonction nécessaire voire indispensable pour le prochain Half-Life 2 et ses futurs dérivés. Cette fonction permet d'éviter les artefacts issus du Multisampling généré par les modes FSAA, en utilisant un échantillon de texture pris au centre d'un triangle. Notez au passage que cette fonction est rendue obligatoire par DirectX 9.0c. Au-delà de cette nouveauté, NVIDIA propose une nouvelle méthode de lissage baptisée Rotated-Grid Antialiasing. Actuellement l'antialiasing s'effectue en utilisant un échantillonnage de quatre sous pixels selon un modèle en forme de carré. Le problème est que cette méthode ne concerne que deux des lignes constituant la forme sélectionnée. En inclinant la sélection, de sorte à former un losange, les GeForce 6 couvrent le même nombre de sous pixels mais avec un échantillonnage sur quatre lignes ce qui permet d'obtenir une meilleure précision des couleurs.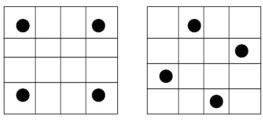
A gauche l'échantillonnage classique, à droite le nouvel échantillonnage
Du coup les anciennes méthodes de type Quicunx ne sont plus disponibles sur les GeForce 6 et il faut se contenter d'un FSAA maximal en 8x (exit le mode 6xS) et, pour la première fois chez NVIDIA, d'un mode Anisotropic en 16x. L'occasion pour nous de voir l'apport de l'Anisotropic filtering 16x avec les captures ci-dessous.



Dans l'ordre : NV38 FSAA 4x & Aniso 8x, NV40 FSAA 4x & Aniso 16x & Radeon 9800 XT FSAA 4x & Aniso 8x
Surprise ! Le rendu du NV38 est strictement identique à celui du NV40 du moins pour la portion d'image que nous avons sélectionnée. Il apparaît dès lors que le effets du mode Anisotropic filtering 16x sont imperceptibles, le destinant donc plutôt au marché de la 3D professionnelle un peu comme ce que l'on observe sur les cartes ATI en activant ce mode particulier. Puisqu'on en est à comparer des rendus avec lissage d'écran on note que dans les mêmes conditions, le rendu d'ATI est plus touffu et semble légèrement plus détaillé. Mais là encore tout est question de goût et il est bien difficile de préférer un rendu à l'autre.
Un VPE nickel chrome
Par le passé, NVIDIA a été vertement critiqué pour le faible nombre de fonctionnalités vidéo qu'il intégrait à ses puces. Il faut dire que là où ATI proposait une décompression MPEG2 matérielle depuis le premier Radeon, il fallu attendre l'arrivée du GeForce FX pour que cette fonction soit disponible sur l'ensemble des puces NVIDIA. Conscient de son retard en matière de vidéo, NVIDIA a redoublé d'efforts pour rattraper son retard avec le NV40. Aussi, la puce comporte un tout nouveau VPE (Video Processor Engine) aux fonctionnalités tout bonnement impressionnantes. Tout d'abord il est important de préciser que contrairement à ATI qui fait appel à un composant externe pour la gestion des fonctions vidéo avec le Rage Theater, le GeForce 6800 intègre directement en son sein le VPE. Celui-ci dispose de fonctions assez inattendues puisqu'outre la décompression matérielle des flux MPEG2, le GeForce 6800 est capable d'encoder des vidéos au format MPEG 2 ! Les possibilités d'encodage et de décodage s'étendent également aux formats MPEG 4, WMV 9 et DivX. Hélas à l'heure actuelle ces fonctions ne sont pas encore implémentées et il est fort possible qu'outre un support dans les pilotes, il faille disposer d'applications spécialement conçues pour prendre en charge le VPE du GeForce 6800 afin de bénéficier de ses optimisations. Actuellement seules les décompressions WMV9 et MPEG2 sont opérationnelles en attendant mieux. Pour l'anecdote sachez que l'encodage MPEG 2 se fait à plus de 60% au niveau du processeur graphique. Durant nos test nous avons tâché de vérifier le gain de performances induit par le décodage matériel offert par le NV40 du format Windows Media 9. Nous avons pour cela utiliser le trailer de Scoobidoo 2 en 720p. En désactivant l'accélération matérielle depuis le lecteur nous obtenons une utilisation CPU moyenne de 50%, contre 40% lorsque le NV40 décharge l'unité centrale. Le gain n'est donc pas fantastique ce qui laisse penser que les Drivers employés sont encore loins d'exploiter correctement ce VPE de nouvelle génération.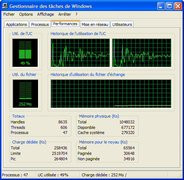
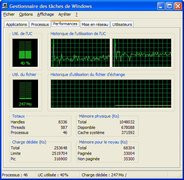
Lecture d'un flux Windows Media 9 : Occupation CPU sans et avec l'accélération matérielle offerte par le NV40
NVIDIA étant une firme américaine, il n'est guère surprenant d'apprendre que l'encodeur TV du NV40 supporte le format HDTV avec une sortie et un décodage MPEG 2 supportant une résolution maximale de 1920x1080. Ajoutons à cela le support de la technologie Microsoft VMR (Video Mixing Renderer) qui permet sur une seule machine dotée d'un GeForce 6800 Ultra de lire en simultané près de 9 streams DVD ! NVIDIA propose en plus une fonction de désentrelacement adaptative, ainsi qu'une remise à l'échelle et un filtrage des vidéos pour toujours obtenir une qualité vidéo maximale qu'importe la taille de la fenêtre et la taille originale de la vidéo. Une fonction de deblocking est également au programme et permet d'enlever les blocs qui apparaissent généralement dans les zones sombres des vidéos encodées au format MPEG 2. Si on ajoute à cette liste déjà éloquente un filtre anti-bruit, une correction gamma et une conversion intégrée des espaces couleurs on comprend très vite que le VPE du NV40 n'est pas là pour faire joli mais bien pour séduire les vidéastes amateurs. D'autant que le GeForce 6800 gère le deblocking et le motion compensation pour le WMV9/H.264 en sus du 3:2 pulldown ! Cette dernière fonction permet d'éviter la répétition des frames tout en réduisant le bitrate pour une meilleure fluidité de lecture lors de la lecture de plusieurs streams en parallèle. La plupart des fonctions énumérées précédemment sera exploitable par l'entremise de Microsoft DirectShow.
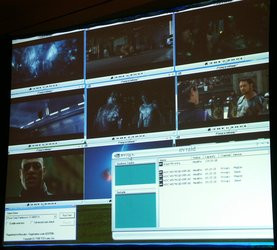
Technologie Microsoft VMR en action sur le NV40 ou comment disposer de 9 streams simultanés
Quelques mots sur la 2D...
Le NV40 comporte, tout comme les GeForce FX, deux RAMDAC, chacun cadencé à 400 MHz. Cela permet au chip de gérer des résolutions extremes de 2048x1536 en 85 Hz. La puce intègre également un TMDS de 185 MHz mais NVIDIA semble préférer l'utilisation de TMDS externes afin d'éviter les problèmes de bruit électronique. Le GeForce 6800 est bien entendu pourvu d'un encodeur TV aux formats PAL/NTSC dont la résolution maximale est de 1024x768 avec un support de la technologie MacroVision. Lors de nos tests nous avons vérifié la qualité de la sortie TV et celle-ci s'est avérée irréprochable tant au niveau de la facilité de mise en oeuvre que de la qualité de l'image affichée. A propos de 2D, NVIDIA a théoriquement conservé son système FlOw Control qui ajuste la fréquence de fonctionnement du processeur en fonction de l'utilisation du système afin de mieux réguler la consommation électrique pour préserver la durée de vie des composants ce qui a pour incidence directe de moduler la vitesse de rotation du ventilateur. Toutefois les fréquences étant encore flottantes au moment où nous avons pu mettre nos mains sur le GeForce 6800, le mode de fonctionnement 2D à fréquence réduite n'était pas encore implémenté. Il paraît sage de tabler sur une fréquence de fonctionnement de 200/250 MHz du NV40 en 2D, mais cela reste à confirmer.ForceWare série 60.xx
Pour l'instant et comme à chaque lancement d'une nouvelle génération de puces graphiques, les pilotes fournis par NVIDIA ne sont pas vraiment optimisés pour tirer le meilleur profit de le nouvelle architecture GeForce 6. NVIDIA travaille en effet sur la prochaine génération des ForceWare, la série 60. Nous avons employé pour ce test les pilotes 60.72 en version beta qui n'apportent que de petites nouveautés. Non encore certifiés WHQL, ces pilotes intègrent un compilateurs PS 3.0 affiné, diverses optimisations, une prise en charge de plusieurs modèles HDTV ainsi qu'une fonction QuickZoom qui permet de rapidement zoomer sur une partie de l'écran. On trouve également dans ces pilotes un assistant de configuration pour régler la sortie TV ou HDTV ainsi que la possibilité de définir soi-même les timings de l'écran avec une précision redoutable. Avec la série 60, NVIDIA supporte l'OpenGL Shading Language et propose une nouvelle version plus complète de la gestion des profils de jeux. Les utilisateurs de Windows Media Center Edition seront en outre ravis d'apprendre que NVIDIA a développé de nouveaux assistants de réglage de l'image offrant une bien meilleure intégration à cette version spécifique de Windows XP.

Un aperçu des ForceWare 60.72
Souvenez-vous, pour obtenir des performances descentes en DirectX 9.0 avec la famille NV3x, NVIDIA procédait au remplacement de shaders dans les Drivers ou à des optimisations directement intégrées dans les jeux. Celles-ci jouaient essentiellement sur l'ordre d'exécution des instructions qui était primordial pour ne pas voir les GeForce FX s'effondrer. Aujourd'hui grâce à sa puissance brute et à son impressionnant nombre de pipelines, le NV40 n'a plus besoin de ces optimisations d'autant que son architecture n'est pas soumise aux mêmes contraintes, même si le support du FP24 n'est toujours pas au rendez-vous. Les optimisations spécifiques aux GeForce FX continueront malgré tout d'exister dans les ForceWare 60.xx et n'auront à priori aucune incidence sur les performances du NV40 et de ses dérivés.
Durant nos tests nous n'avons rencontré aucun problème de compatibilité majeure avec la plupart des titres récents (Far Cry, Prince Of Persia Sands Of Time, Splinter Cell : Pandora Tomorrow, Rise Of Nations, Age Of Mythology, Need For Speed Underground, etc.), à l'exception notable de GunMetal qui disparaît de l'écran aussitôt après s'être lancé. Les ForceWare 60.72 sont l'occasion pour NVIDIA de restaurer le filtrage trilinéaire, du moins uniquement pour les GeForce 6.
NVIDIA GeForce 6800 Ultra : la carte
Après avoir compulsé en long, en large et en travers, l'impressionnante liste des fonctionnalités du NV40 ou plutôt du GeForce 6800 Ultra, on se dit que la carte de référence est forcément un monstre. NVIDIA nous a en effet habitué, depuis feu le GeForce FX 5800, à nous concocter des cartes pachydermiques aux systèmes de refroidissement toujours plus élaborés et massifs. Le premier contact avec le GeForce 6800 Ultra est rassurant puisque la carte conserve les mêmes dimensions que les GeForce FX 5700 Ultra ou 5900 Ultra avec une profondeur de -seulement- 21.5 cm. La carte est dotée d'un PCB vert comportant huit couches. Passé cette première -bonne- surprise, on découvre avec effroi que la dite carte est pourvue de deux connecteurs Molex ! Il est en pratique indispensable de raccorder deux connecteurs à la carte pour que celle-ci ait suffisamment de puissance pour fonctionner correctement. Mais contrairement aux NV35 et NV38 qui disposaient tous deux d'un imposant bloc d'alimentation, le GeForce 6800 Ultra est pour sa part doté d'un nombre réduit de composants gérant l'alimentation. Les sorties offertes par la carte sont tout aussi surprenantes puisque pour la première fois, NVIDIA propose sur une carte haut de gamme (non destinée au monde professionnel) une double connectique DVI. L'adaptateur DVI/VGA sera donc indispensable si vous disposez encore d'un bon vieux CRT. Ajoutons qu'une sortie TV est également présente à l'arrière de la carte.

Une bien belle carte !
Le système de refroidissement employé par NVIDIA sur sa carte de référence est pour une fois modeste. Il est en effet constitué d'un simple radiateur métallique surplombant la puce et recouvert d'une gaine en plastique à l'extrémité de laquelle souffle un large ventilateur. L'air chaud est ici expulsé à l'arrière de la carte en passant par divers radiateurs. Du côté de la mémoire on voit ici les bénéfices de la DDR3. Chaque composant faisant 256 Mbits, il ne faut que huit puces pour offrir une capacité de 256 Mo, du coup la face arrière de la carte ne comporte aucune puce mémoire ni système de refroidissement. En outre nous avons pu constater que contrairement à la DDR2, la DDR3 chauffe très peu. Pourtant, malgré la simplicité apparente du refroidissement employé sur les puces mémoire, NVIDIA a tout de même opté pour une plaque métallique munie de radiateurs plus ou moins importants et traversée par un heat-pipe sur toute sa longueur. Le radiateur dédié à la mémoire repose sur des pads thermiques protégeant les puces. NVIDIA utilise ici des composants Samsung au format FBGA certifiés à 500 MHz mais cadencées à 550 MHz avec une tension de 1.8 volts. Physiquement, la carte n'occupe qu'un seul slot mais son imposant radiateur condamnera vraisemblablement un port PCI. A l'usage on s'aperçoit rapidement que le ventilateur du NV40 est bruyant. Bien sûr on est très loin du NV30, mais le GeForce 6800 fait dans sa version actuelle plus de bruit qu'un GeForce FX 5900/5950 ou qu'une Radeon 9800XT. NVIDIA nous indique toutefois que le système de refroidissement actuellement employé sur les cartes de référence est amené à évoluer vers une version single slot plus discrète comme vous pouvez l'apercevoir sur les photos.


Plus de détails du GeForce 6800 Ultra
Dépourvue de fonctions VIVO, la carte de référence NVIDIA fait appel à deux TMDS Silicon Image pour gérer les sorties DVI ce qui est censé produire une meilleure qualité d'affichage. Chose étonnante pour une carte graphique, le GeForce 6800 est muni d'une sorte de buzzer à l'utilité franchement peu évidente (alerte en cas de surchauffe, utile uniquement pour le debugging, etc ?). Sachez enfin que notre GeForce 6800 était muni de la révision A1 du NV40 celle-ci ayant été jugée suffisamment stable pour être commercialisée.
Quid de la qualité du rendu ?
Au delà des performances, la qualité de rendu délivrée par une puce 3D reste un paramètre important dans le choix de celle-ci. Par le passé nous avons pu voir divers constructeurs, et pas forcément les plus anodins, tricher en diminuant la complexité graphique des scènes pour obtenir de meilleurs scores. Aussi quelques vérifications s'imposent du côté de la qualité graphique en utilisant 3DMark 2003.


NVIDIA GeForce FX 5950 Ultra, NVIDIA GeForce 6800 Ultra, ATI Radeon 9800 XT
En observant attentivement ces screenshots on note quelques minimes différences entre le rendu du NV38 et du NV40. Ce dernier semble traiter avec plus de précisions les contours de certains objets et notamment les pierres agrémentant le ruisseau. Face au Radeon 9800 XT, les différences sont minimes et tout se joue sur la définition du bord des objets. Dès lors il apparaît bien difficile de préférer l'un ou l'autre des rendus tant les différences sont infimes.

- Asus P4C800 Deluxe (rev2)
- Intel Pentium 4C 3.2 GHz
- 2x256Mo Corsair Twinx 3200 LL (CAS 2)
- Disque dur Seagate 120Go UDMA100 7200rpm
3DMark 2001 SE
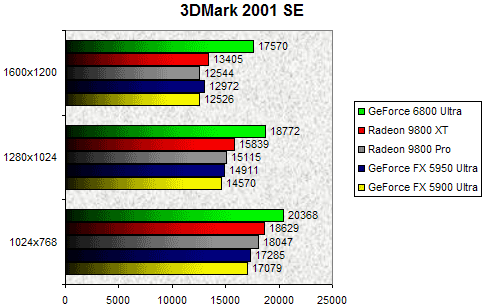
Commençons par un classique du genre avec le vénérable 3DMark 2001 SE. Histoire de vérifier les aptitudes DX8 de nos diverses cartes. Ici, le dernier bébé de NVIDIA domine clairement l'épreuve avec des scores assez impressionants. Largement devant le Radeon 9800 XT, il est intéressant de constater que le GeForce 6800 Ultra maintient un excellent niveau de performances avec l'augmentation de la résolution. Pour les amateurs de chiffre, on retiendra que le GeForce 6800 Ultra est 18% plus rapide que le Radeon 9800 XT en 1280x1024 et cet écart montre à 31% en 1600x1200 ! Le NV40 semble donc taillé pour les résolutions extrêmes puisqu'entre le mode 1024x768 et le 1600x1200 ses performances ne baissent que de 16%, là où un NV38 perdait 33%.
Return To Castle Wolfenstein
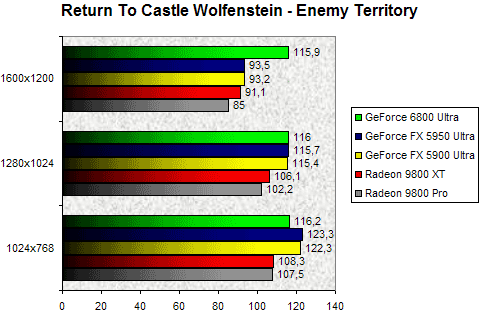
Enchaînons avec Return To Castle Wolfenstein, jeu OpenGL par nature. Rappelons au passage que nous utilisons ici notre propre démo et que le moteur graphique est poussé dans ses derniers retranchements avec l'activation de toutes les options. A la première lecture du graphique, il est surprenant de constater qu'en 1024x768, le GeForce 6800 Ultra se fait légèrement devancé par les GeForce FX 5900 Ultra & 5950 Ultra. Toutefois, on constate très vite que le NV40, s'il cède la première place en 1024x768, reste le plus performant des Processeurs graphiques retenus puisqu'en résolution maximale (1600x1200) son framerate ne bouge pas d'un iota avec un score hallucinant de 115.9 FPS, là où le NV38 plafonne à 93 fps. Cela tend à prouver que le facteur limitant, au niveau des performances, est ici le processeur. En outre ce test est particulièrement intéressant puisqu'il montre clairement que la montée en résolution ne grève nullement les performances de la puce. Ici, le GeForce 6800 Ultra est 27% plus véloce que le Radeon 9800 XT ce qui n'est pas forcément représentatif dans la mesure où les VPU ATI sont historiquement peu performants en OpenGL. Face au NV38, le NV40 s'adjuge un score 24% plus élevé.
3DMark 2003 - Build 340
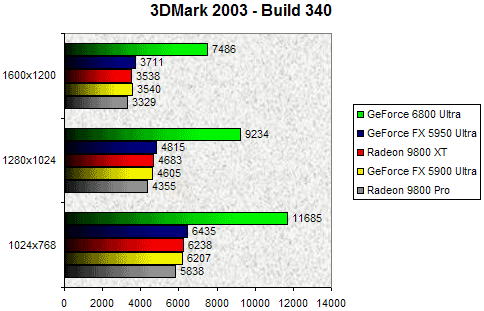
Dernière version en date de 3DMark, la version 2003 a été à plusieurs reprises contestée tant pour sa pertinence que pour les optimisations apportées par les divers constructeurs pour mettre en avant leurs puces. Nous ne reviendrons pas sur cette histoire qui a déjà fait couler beaucoup (trop) d'encre virtuelle, pour nous concentrer sur les résultats obtenus. Quelques jours avant le lancement, un chiffre de 12000 points était sur les lèvres de beaucoup grâce à une rumeur d'un site anglophone. La rumeur était vraisemblablement fondée puisque le GeForce 6800 Ultra s'adjuge ici le score record de 11685 points soit près de deux fois le score d'un Radeon 9800 XT ! Cette prouesse peut s'expliquer par la profondeur du pipeline, le fillrate élevé et l'architecture du NV40 qui rappelons le dispose de deux unités de shaders par TMU. NVIDIA domine donc la concurrence avec son GeForce 6800 Ultra et ce quelque soit la résolution. Même en 1600x1200 le GeForce 6800 Ultra se montre deux fois plus rapide que le Radeon 9800 XT !
AquaMark 3.0
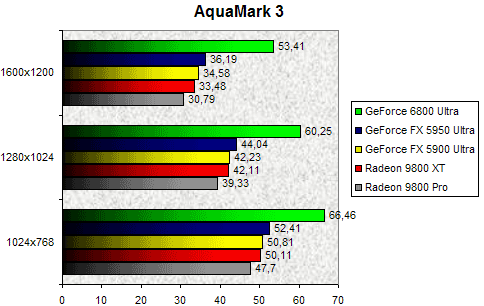
AquaMark 3.0, qui est rappelons le un test basé sur DirectX 9.0 et faisant appel aux Pixel Shaders 2.0, confirme la suprématie du NV40 qui survole nettement la compétition. Quelque soit la résolution le GeForce 6800 Ultra est en tête, preuve s'il en est de l'efficacité de la nouvelle architecture de NVIDIA et de sa puissance pour la gestion des shaders. Face à un Radeon 9800 XT, le GeForce 6800 Ultra est 59% plus rapide en 1600x1200. Comparé au GeForce FX 5950 Ultra, ici représenté par une carte Leadtek, le dernier poulain de NVIDIA est 48% plus rapide.
Far Cry
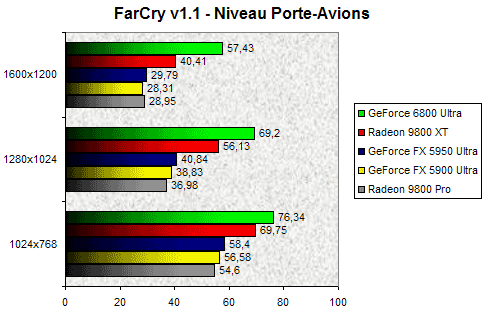
Jeu très attendu, Far Cry est en passe de voler la vedette aux (futures) hits du genre qui se font désirer comme Doom III et Half-Life 2. Au delà de ces considérations marketing, Far Cry surprend par la beauté de ces paysages idylliques et par la complexité de ses scènes. Il faut dire que les développeurs de Crytek n'ont pas lésiné sur l'utilisation des Pixel Shader 2.0 ce qui met en difficulté les Cartes Graphiques DirectX 9.0 de première génération. Il était donc particulièrement intéressant de voir le comportement du NV40 avec ce jeu. Notez que nous utilisons pour ce test une démo de notre cru. En toute logique, le GeForce 6800 Ultra impose sa loi et si son avance sur le Radeon 9800XT reste assez modeste en 1024x768 (seulement 9.5%), il creuse l'écart à chaque nouvelle résolution. Le GeForce 6800 Ultra est donc le premier processeur graphique, à l'exception il est vrai du Radeon 9800 XT, qui permet de réellement jouer avec fluidité à Far Cry en 1280x1024 tous détails activés. Par rapport au GeForce FX 5950 Ultra, aux performances assez médiocres sous Far Cry, le GeForce 6800 Ultra est tout simplement deux fois plus rapide ! Pour ceux d'entre vous qui se demandent pourquoi il y a un tel écart entre le Radeon 9800 Pro et le Radeon 9800 XT, la réponse se trouve dans la quantité de mémoire vidéo disponible sur la carte. Far Cry est en effet beaucoup plus à l'aise avec 256 Mo (Radeon 9800XT) de frame buffer qu'avec 128 Mo (Radeon 9800 Pro).
FireStarter
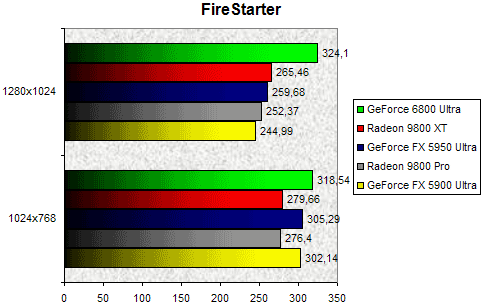
FireStarter fait partie de la nouvelle génération de jeux DirectX 9.0, même s'il n'utilise pas avec autant d'intensité les lourdes fonctions de la dernière API en date de Microsoft. En 1024x768 les résultats sont assez chaotiques : le GeForce 6800 Ultra est bien en tête mais les GeForce FX l'emporte face au 9800 XT d'ATI. C'est donc avec le 1280x1024 que les résultats deviennent vraiment intéressants. On y découvre un Radeon 9800 XT qui reprend des couleurs en dominant les GeForce FX. La puce d'ATI ne peut toutefois rien face au GeForce 6800 Ultra qui d'ailleurs affiche des performances plus élevées qu'en 1024x768... Le NV40 se montre finalement 22% plus véloce que le R360.
Splinter Cell
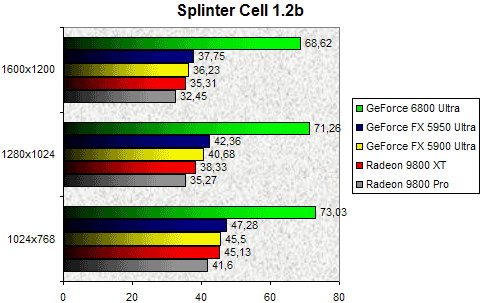
Les jeux DirectX 9.0 ne courent pas encore les rues, aussi il reste intéressant d'étudier les performances de nos diverses cartes avec un jeu DirectX 8.0 utilisant les Pixel Shaders de première génération. Ici, la domination du GeForce 6800 Ultra est sans partage et à la lecture de ses résultats il semblerait que le CPU ne soit pas assez puissant pour que le NV40 délivre son plein potentiel. Par rapport à une Radeon 9800 XT, le GeForce 6800 Ultra est tout simplement deux fois plus rapide, alors qu'il est 68% plus véloce que le GeForce FX 5950 Ultra en 1280x1024. Le gain que nous observons est donc massif et on ne peut que féliciter NVIDIA.
Tomb Raider - L'ange des ténèbres
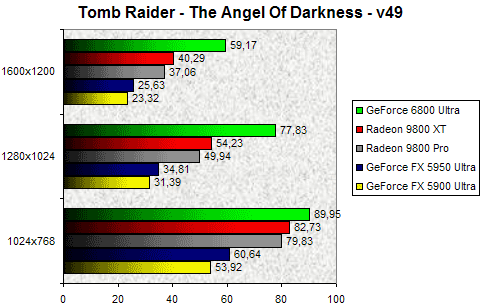
A sa sortie, le dernier opus des aventures de la belle Lara, a défrayé la chronique à cause d'un patch apportant un mode Benchmark. Le mode de benchmark n'est pas vraiment le problème à l'origine de la polémique, c'est plutôt le fait que ce jeu 'NVIDIA - The Way It's Meant To Be Player' tournait en vérité mieux sur les cartes ATI que sur les cartes NVIDIA. Chose qui se perpétue encore aujourd'hui, les Radeon 9800 XT & 9800 Pro étant largement devant les GeForce FX 5900/5950 Ultra. Si en 1280x1024, le Radeon 9800 XT est 56% plus performant que le GeForce FX 5950 Ultra, le GeForce 6800 Ultra renverse la vapeur. Celui-ci se montre en effet 44% plus rapide que le dernier VPU d'ATI et cet écart s'accentue encore en 1600x1200 pour atteindre 47%.
Unreal Tournament 2003
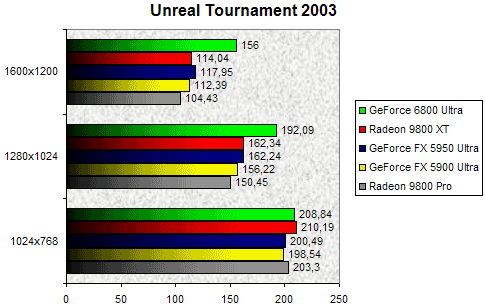
A l'origine nous prévoyions d'utiliser Unreal Tournament 2004 pour ce test. Hélas les résultats obtenus sont bien souvent farfelus, aussi nous avons préféré conserver l'ancienne version, dont le moteur graphique reste identique à celui animant la dernière mouture du jeu. Là encore on peut voir qu'en 1024x768, le GeForce 6800 Ultra est limité par la puissance de notre configuration et affiche un résultat très légèrement inférieur à celui d'un Radeon 9800 XT. En augmentant la résolution, notre GeForce 6800 Ultra reprend de son éclat puisqu'il mène clairement la danse. Dans ce que nous qualifierons de résolution intermédiaire, le 1280x1024, le NV40 surpasse les Radeon 9800 XT et GeForce FX 5950 Ultra de 18%. En 1600x1200, le GeForce 6800 Ultra laisse sur place ses rivaux en se montrant 37% plus performant que le Radeon 9800 XT.
X2 : The Threat
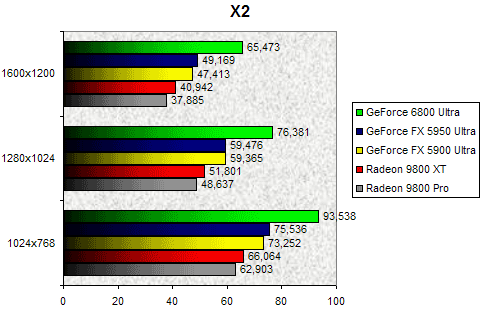
X2 ne fait que confirmer nos observations précédentes sur la puissance du GeForce 6800 Ultra en propulsant celui-ci largement en tête. En 1280x1024, le NV40 est 28% plus rapide que son prédécesseur le GeForce FX 5950 Ultra et s'avère 48% plus rapide que le Radeon 9800 XT. Le fait de passer en 1600x1200 ne change rien aux résultats puisqu'hormis une diminution logique du nombre de FPS, le GeForce 6800 Ultra reste largement en tête.
3DMark 2001 SE - FSAA 4x
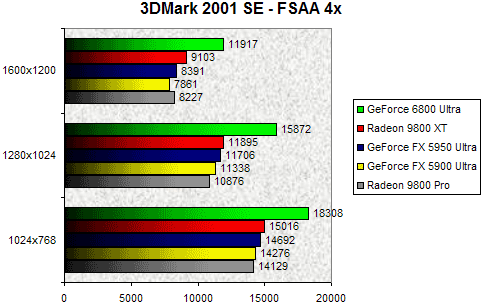
Le GeForce 6800 Ultra étant clairement destiné aux hardcore gamers, il nous faut voir ses performances en matière d'antialiasing. Nous commencerons gentiment avec un petit 3DMark 2001 SE. Le GeForce 6800 Ultra est là encore indétronable avec un net avantage sur le Radeon 9800 XT. En 1280x1024 on peut voir que les performances du GeForce 6800 Ultra sont 34% supérieures à celles du R360. On remarque toutefois un petit tassement en 1600x1200 où le NV40 n'est plus que 30% supérieur au Radeon 9800 XT.
Return To Castle Wolfenstein - FSAA 4x

Voyons maintenant le comportement de nos GPU/VPU en OpenGL avec le FSAA 4x activé. Sans surprise le GeForce 6800 Ultra garde le cap avec d'excellentes performances qu'importe la résolution. Le dernier bébé de NVIDIA se détache nettement des précédentes générations et arrive à imposer sa loi sur les Radeon d'ATI. A titre d'information le GeForce 6800 Ultra est 30% plus rapide que le GeForce FX 5950 Ultra et 52% plus performant que le Radeon 9800 XT. Au vu des framerates relevés Return To Castle Wolfenstein reste jouable sur toutes nos cartes haut de gamme, mais sa fluidité sera naturellement meilleure avec le GeForce 6800 Ultra.
Return To Castle Wolfenstein - FSAA 4x + Aniso 8x
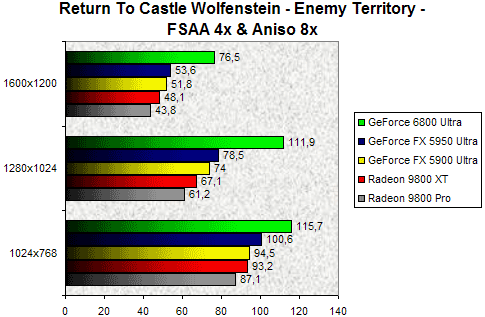
Corsons un peu l'exercice en cumulant lissage d'écran 4x et Anisotropic filtering 8x. La lourdeur de la tâche n'effraye nullement le GeForce 6800 Ultra qui caracolle tout simplement en tête sans être inquiété par aucun des GPU retenus. Le NV40 est ici 43% plus performant que son challenger direct, le GeForce FX 5950 Ultra, en 1280x1024 ! Dans cette même résolution le GeForce 6800 Ultra est pratiquement deux fois plus rapide que le Radeon 9800 XT. Enfin en 1600x1200, le GeForce 6800 Ultra reste largement en tête même si son avance à tendance, et c'est naturel, à se réduire quelque peu.
FarCry - FSAA 4x + Aniso 8x
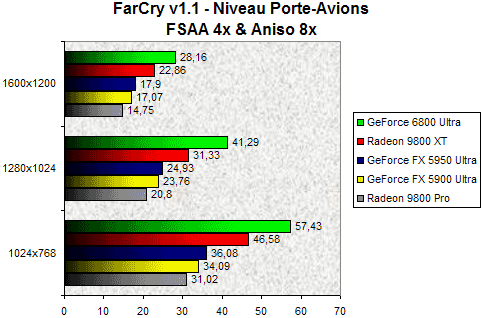
En lisant le simple titre de ce test, certains pourraient être tenté de crier au fou ! En effet quand on observe le comportement de Far Cry sur une carte graphique haut de gamme il paraît suicidaire de vouloir activer les réputées gourmandes options de lissage d'écran. Pourtant cet exercice s'impose de lui même pour un GPU de nouvelle génération. Sans grande surprise, le GeForce 6800 Ultra maintient un très bon niveau de performances en terminant premier qu'importe la résolution. Si les GeForce FX et le Radeon 9800 Pro s'écroulent totalement, seul le Radeon 9800 XT est en mesure de taquiner la dernière vedette de NVIDIA. Mais quand bien même, l'écart entre les deux cartes est de 32% en 1280x1024 en faveur du NV40, alors que ce dernier atomise le GeForce FX 5950 Ultra avec un score 66% supérieur ! S'il n'est pas possible de jouer dans de bonnes conditions à Far Cry avec le lissage d'écran et les cartes GeForce FX 5900/5950 Ultra & Radeon 9800 Pro, le GeForce 6800 Ultra permet à n'en pas douter de goûter aux plaisirs d'une définition graphique encore plus élaborée.
Notez qu'en 1600x1200 l'avantage du GeForce 6800 Ultra semble bien maigre face au Radeon 9800 XT (environ 6 FPS de mieux). Cette contre-performance peut s'expliquer par la quantité limitée de mémoire vive de notre machine ; seulement 512Mo alors que FarCry est précisément très gourmand en mémoire vive.
Conclusion

Mais les ingénieurs de la firme ne se sont pas arrêtés à la puissance brute puisqu'ils ont également intégré le support du Shader Model 3.0 qui sera exploité par les futurs jeux et par DirectX 9.0c qui exige une précision de calcul en 128 bits (FP32). Voilà une belle façon pour NVIDIA de démontrer qu'il n'avait pas forcément tort d'opter dès le départ pour le FP32 même si cela lui à coûté très cher : près de 100 à 200 millions de dollars de l'aveu même de Jen-Hsun Huang. Sans révolutionner le genre, la version 3.0 des shaders devrait permettre aux développeurs de regrouper plusieurs shaders en un seul ce qui devrait améliorer sensiblement les performances de leurs jeux tout en leur facilitant la tâche, du moins en principe. Comme si cela ne suffisait pas, le GeForce 6800 Ultra intègre un processeur vidéo aux fonctionnalités pour le moins épatantes, du moins sur le papier, puisque la première génération des Drivers ForceWare 60, ne permet pas encore d'en tirer la quintessence.
Arrêtons ici les louanges pour parler des regrets que nous pouvons avoir au sujet du NV40. Si le GeForce 6800 Ultra semble d'après nos tests être effectivement un vrai big bang en terme de performances, cette puissance a un coût. Non seulement les GeForce 6800 Ultra se négocieront dans un premier temps aux alentours des 550€ mais il faudra en plus disposer d'une alimentation de 450 Watts pour espérer les exploiter convenablement. En outre, la fréquence initiale de 400 MHz nous paraît un peu faible ce qui signifie potentiellement trois choses : soit NVIDIA se conserve une confortable marge de manœuvre pour faire évoluer dans le futur la fréquence de son GPU vedette, soit le yield (chip exploitable en sortie d'usine) au-delà de 400 MHz serait trop peu élevé, soit les fuites d'électrons au sein du GPU sont trop importantes à cause du nombre élevé de transistors, et seul le procédé Low-K pourra éventuellement aider NVIDIA à rectifier le tir. Une autre hypothèse peut aussi être retenue : l'architecture du NV40 nécessite pour monter encore plus en fréquence une mémoire plus rapide or à l'heure actuelle la GDDR3 à plus de 600MHz n'est pas encore disponible en volume... Nous n'évoquerons pas non plus le problème du système de refroidissement qui cumule deux défauts : une taille imposante et un bruit élevé, du moins sur le prototype en notre possession. Heureusement NVIDIA devrait prochainement proposer un nouveau système de refroidissement, compact et discret, nous dit-on.
Pour finir, le GeForce 6800 Ultra est une merveille technologique aux performances ahurissantes. Il ne fait aujourd'hui aucun doute que cette carte représente une avancée majeure et ce à tous les niveaux. Reste maintenant à voir comment réagira ATI avec son X800 pour se prononcer définitivement sur ce très prometteur GeForce 6800 Ultra dont la disponibilité devrait intervenir d'ici un bon mois.
