

En cette rentrée NVIDIA semble décidé à renouveler son offre haut de gamme et lance, enfin, Maxwell sur ce créneau avec deux nouvelles références : les GeForce GTX 970 et 980. On note au passage que la dénomination commerciale fait un bond : il n'y aura donc pas de GeForce 800 sur les PC de bureau... du moins pour le moment, sait-on jamais !
Ces deux nouvelles GeForce sont basées sur une puce qui profite d'une nouvelle architecture ici implémentée pleinement. Alors que NVIDIA évoque une prise en charge de DirectX 12, nous aurons à cœur de vérifier le comportement des GeForce 900 en matière de performance par watt, un critère sur lequel NVIDIA est très attendu.
Carte graphique : découvrez des offres à bas prix sur notre comparateur de prix !

Architecture Maxwell : vue d'ensemble
Avec Maxwell, NVIDIA ne change pas fondamentalement la donne par rapport à ses précédentes architectures et notamment face au Kepler des GeForce 600 et 700. On conserve donc un découpage de la puce en larges unités, les GPC ou Graphic Processing Cluster. On dénombre un total de 4 GPC au cœur de la GeForce GTX 980. Chaque cluster comporte quatre pool de SM ou Streaming Multiprocessors (et non plus SMX), chacun avec 128 cœurs CUDA, 8 unités de texture et quatre contrôleurs mémoire 64 bits, en plus bien sûr du PolyMorph Engine. À partir de ces quelques données brutes, on se fait vite une idée de la puce et de ses caractéristiques.Dans sa version la plus évoluée, la puce GM204 peut tabler sur 2048 processeurs CUDA, 128 unités de texture et un bus mémoire de 256 bits. Ce dernier point nous rappelle d'emblée que la GeForce GTX 980 vise bien à prendre la relève de la GeForce GTX 680 et sa puce GK104 qui était elle aussi dotée d'un bus mémoire 256 bits. Les variantes de GeForce autour de la puce GK110, comme les GeForce GTX 770 et 780 pouvaient elles s'appuyer sur un bus mémoire 384 bits. Gageons que si le bus mémoire n'évolue pas avec le GM204, NVIDIA a mis en place diverses solutions pour booster la bande passante mémoire.

Justement, NVIDIA a revisité l'organisation de la partie mémoire de la puce. Chaque contrôleur est ainsi relié à 16 unités ROP avec 512 Ko de mémoire cache de second niveau. En tout, la puce GM204 dispose de 64 unités ROP et 2 Mo de cache L2. À titre de comparaison, la puce GK104 du GeForce GTX 680 ne comptait que 32 unités ROP et 512 Ko de cache. Les GeForce les plus rapides basées sur le GK110 doivent se contenter de 48 unités ROP et 1,5 Mo de cache L2. Un vrai progrès donc, d'autant que le cache additionnel, probablement moins coûteux à implémenter que précédemment, devrait contribuer à réduire la pression sur le bus mémoire en allégeant notamment le nombre de requêtes : pas besoin d'aller chercher des données en mémoire si elles sont déjà dans le cache.
Côté géométrie, la puce GM204 est pourvue de deux fois plus d'unités que le GK104 des GeForce GTX 680. NVIDIA annonce a minima une performance géométrique logiquement doublée avec dans certains cas des performances jusqu'à trois fois supérieures.
Architecture Maxwell : la même en mieux
Nous l'évoquions, l'architecture Maxwell ne représente pas un bouleversement par rapport aux précédentes architectures GeForce. Toutefois si les schémas se ressemblent, il faut avoir en tête le but de NVIDIA : augmenter la capacité de traitement de la puce face au GK104 sans pour autant augmenter sa complexité. Pour être en mesure de revendiquer l'intégration de deux fois plus de SM sans avoir fait exploser la taille du die, NVIDIA a dû passer par la refonte d'un certain nombre d'éléments...... à commencer par le scheduler de chaque SM. Celui-ci bénéficie d'une nouvelle conception visant à accroître son efficacité dans la répartition des tâches. Puisque chaque opération effectuée par la puce va à un moment ou un autre passer par le SM, il faut un bloc pour répartir les instructions en direction des cœurs CUDA notamment. C'est le rôle du scheduler : on en trouve quatre par SM, chacun pouvant envoyer deux instructions par cycle d'horloge.
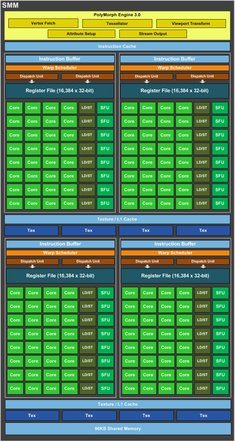
Gros plan sur un SMM
Face à Kepler, le scheduler est d'autant plus efficace que l'agencement des SM a évolué. Précédemment, les 192 cœurs CUDA de chaque SM pouvaient être adressés indifféremment. Ils sont aujourd'hui rationalisés et moins nombreux. Chaque SM compte 128 cœurs CUDA et ceux-ci sont subdivisés en quatre groupes de 32 cœurs, chacun avec son scheduler. Un redécoupage avec un fonctionnement en silo qui affecte la hiérarchie mémoire : la mémoire cache de premier niveau rejoint le bloc de texture alors que l'on dispose maintenant de 96 Ko de mémoire partagée par SM.
Une mémoire plus efficace
Nous l'écrivions plus haut, Maxwell dispose d'une interface mémoire 256 bits. Ce n'est clairement pas le nec plus ultra en la matière et pour compenser cela NVIDIA a revisité le fonctionnement du système mémoire. L'augmentation de la quantité de mémoire cache de second niveau à 2 Mo devrait aider aux performances mémoire tout comme l'utilisation de mémoire GDDR5 rapide.Mais NVIDIA met en place de nouveaux algorithmes. Afin de réduire la bande passante mémoire utilisée, la puce fait appel à une compression sans perte des données qui devront être écrites en mémoire. En fonction de la composition des données à écrire en mémoire, une compression avec un ratio différent est appliquée.

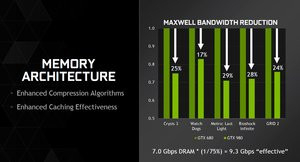
Depuis les puces GeForce de génération Fermi, NVIDIA utilise également la compression delta. Il s'agit toujours de préserver la bande passante mémoire en n'enregistrant pas directement les informations de couleur d'un pixel mais plutôt la différence de couleur par rapport à d'autres pixels. Les résultats sont ensuite regroupés pour minimiser l'empreinte mémoire. NVIDIA propose avec Maxwell sa troisième génération algorithme de compression delta avec, nous dit-on, une efficacité accrue.
DirectX 12 en ligne de mire
Même si Microsoft n'a toujours pas finalisé les spécifications de DirectX 12, l'éditeur a commencé à dévoiler quelques-unes des fonctionnalités introduites par sa nouvelle API. Rappelons avant tout que le but numéro un de DirectX 12 est de réduire l'overhead CPU à la manière d'un certain Mantle d'AMD. En clair, faire en sorte que les appels DirectX consomment moins de ressources processeur et soient traités avec plus de célérité. Pour cela, Microsoft délègue le contrôle du couple GPU/CPU aux développeurs et non plus aux seuls pilotes de la carte graphique.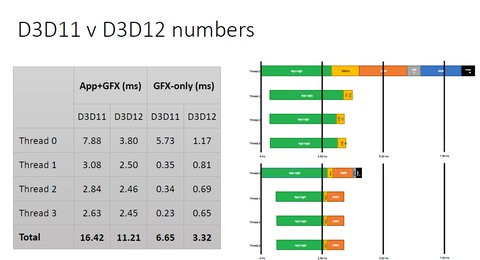
Au-delà de cette vision globale, la nouvelle API du géant de Redmond que l'on devrait retrouver au cœur du prochain Windows introduit de nouvelles fonctions. Tandis que les optimisations évoquées plus haut bénéficieront à toutes les puces graphiques existantes, les nouvelles fonctionnalités exigent logiquement une prise en charge matérielle et donc une nouvelle carte graphique.
Parmi celles-ci, Microsoft évoque le Raster Ordered View, une nouveauté qui concerne le traitement, dans l'ordre, des shaders qui arrivent dans les ROP, ces unités de la puce graphique qui prennent en charge les dernières opérations à appliquer à nos pixels. DirectX 12 va également proposer ce qu'on appelle les « Conservative Raster ». Il s'agit ici d'un algorithme alternatif pour la rastérisation des triangles, c'est-à-dire leur conversion d'une image vectorielle à une image matricielle. Un algorithme dont la méthode de calcul est plus précise et peut s'avérer utile dans le cadre de la voxelisation pour tout ce qui concerne l'éclairage d'une scène.

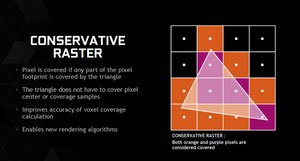
Rappelons qu'un voxel, ou volumetric pixel, est un cube. C'est-à-dire qu'à l'inverse d'un pixel qui représente un point 2D dans l'espace, un voxel est un volume 3D. Pour arriver à une illumination globale la scène est alors entièrement décomposée en cubes, les voxels : la voxélisation c'est donc le procédé qui consiste à déterminer le contenu de la scène pour chaque voxel. Et la technique « Conservative Raster » introduite par le prochain DirectX 12 doit permettre de déterminer plus précisément quel voxel est recouvert par un triangle.
Maxwell qualité filtre : du neuf pour la qualité d'image
NVIDIA tente également d'innover avec Maxwell du point de vue du rendu de l'image, afin d'en améliorer toujours sa qualité. La marque propose une énième nouvelle façon de lisser les effets d'escalier qui peuvent apparaître dans les scènes de nos jeux favoris. Aux côtés des récents FXAA et SMAA notamment, NVIDIA pose les bases du Multi-Pixel Programmable Sampling, à ne pas confondre avec l'historique MSAA. Avec l'anticrénelage conventionnel, le MSAA, la puce graphique utilise des samples fixes pour opérer l'anticrénelage.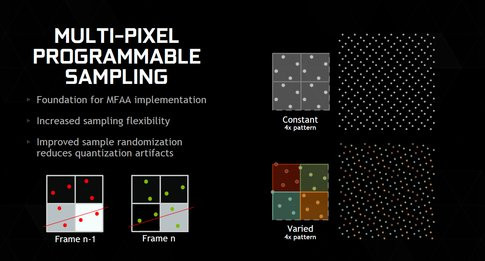
Par le biais du Multi-Pixel Programmable Sampling NVIDIA donne la possibilité de programmer le motif de samples qui servira à l'anticrénelage et ce depuis le pilote ou depuis l'application. La position des samples peut alors varier d'une image à l'autre et s'étendre sur plusieurs pixels. C'est la base d'un nouvel algorithme développé par NVIDIA, le MFAA ou Multi-Frame Sampled AA : on alterne ici les samples AA dans le temps et l'espace avec pour avantage un gain de qualité et un gain de performance, la pénalité étant moindre. NVIDIA avance qu'il peut proposer en MFAA un rendu proche de la qualité traditionnelle en MSAA 4x avec le coût d'un MSAA 2x. Du moins sur le papier car les pilotes de lancement de la GeForce GTX 980 n'activent pas encore cette fonction. Il nous faudra donc être patients.
Une autre technique proposée par NVIDIA et réservée à Maxwell est le Dynamic Super Resolution. Il s'agit tout simplement d'opérer le rendu 3D en résolution 4K et de l'afficher via downsampling sur un écran HD à la résolution conventionnelle. L'avantage est bien sûr une image de meilleure qualité d'autant que NVIDIA utilise ici un filtre gaussien avancé pour éliminer certains artefacts que l'on peut voir via un downsampling conventionnel. Pourquoi pas... Cette fonctionnalité est intégrée au GeForce Experience mais également activable et paramétrable depuis le pilote NVIDIA traditionnel. Une fonction qu'on retrouvera d'ailleurs sur tous les GPU GeForce et pas seulement Maxwell.
Du neuf pour la vidéo et l'affichage
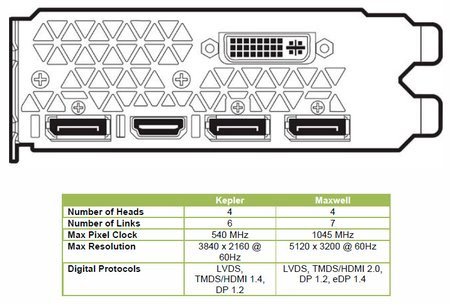
Alors que le GeForce GTX 750 Ti nous avait laissé sur notre faim pour tout ce qui concerne l'affichage et la compression vidéo, NVIDIA dote Maxwell d'un nouveau moteur d'affichage pour sa puce GM204.Celui-ci va au-delà de la 4K et supporte un affichage 5K. Mieux, il est possible de piloter un total de quatre écrans 4K depuis un seul GPU (Kepler ne peut piloter que deux écrans 4K). La puce GM204 supporte aussi pour la première fois chez NVIDIA la norme HDMI 2.0 permettant d'envoyer des flux 4K pleine résolution à 60 Hz.
L'encodeur vidéo NVENC profite également d'améliorations. La plus attendue est la prise en charge de l'encodage H.265 également appelé HEVC. NVIDIA évoque également des performances accrues pour son encodeur H.264 avec un débit 2,5 fois supérieur à celui de Kepler.
GeForce GTX 980 et GTX 970 : puce et fréquences
La puce GM204 qui anime la nouvelle GeForce GTX 980 est toujours gravée en 28nm par TSMC. S'il n'y pas d'avancées sur le processus de fabrication, elle compte la bagatelle de 5,2 milliards de transistors.Du côté des fréquences de fonctionnement, NVIDIA cadence la GeForce GTX 980 à 1126 MHz avec une fréquence Boost à 1216 MHz. Et tandis que la GeForce GTX 980 peut compter sur 2048 processeurs CUDA, on n'en compte plus que 1664 pour la GeForce GTX 970. Celle-ci tourne à 1050 MHz avec un Boost à 1178 MHz.
Pour les deux puces NVIDIA propose une fréquence de 1750 MHz pour la mémoire GDDR5, présente à hauteur de 4 Go par carte, qu'il s'agisse de la GeForce GTX 970 ou de la GTX 980.
| Radeon R9 290 | Radeon R9 290X | GeForce GTX 780 | GeForce GTX 780 Ti | GeForce GTX Titan | GeForce GTX 970 | GeForce GTX 980 | |
| Interface | PCI-Ex. 16x - Gen3 | PCI-Ex. 16x - Gen3 | PCI-Ex. 16x - Gen3 | PCI-Ex. 16x - Gen3 | PCI-Ex. 16x - Gen3 | PCI-Ex. 16x - Gen3 | PCI-Ex. 16x - Gen3 |
| Gravure | 0,028 µ | 0,028 µ | 0,028 µ | 0,028 µ | 0,028 µ | 0,028 µ | 0,028 µ |
| Transistors | 6,2 Milliards | 6,2 Milliards | 7,1 Milliards | 7,1 Milliards | 7,1 Milliards | 5,2 Milliards | 5,2 Milliards |
| T&L | DirectX 11.2 | DirectX 11.2 | DirectX 11 | DirectX 11 | DirectX 11 | DirectX 12 | DirectX 12 |
| Stream Processors | 2560 | 2816 | 2304 | 2880 | 2688 | 1664 | 2048 |
| Unités ROP | 64 | 64 | 48 | 48 | 48 | 64 | |
| Unités de texture | 160 | 176 | 192 | 240 | 224 | 104 | 128 |
| Mémoire embarquée | 4096 Mo | 4096 Mo | 3072 Mo | 3072 Mo | 6144 Mo | 4096 Mo | 4096 Mo |
| Interface mémoire | 512 bits | 512 bits | 384 bits | 384 bits | 384 bits | 256 bits | |
| Bande passante | 320 Go/s | 320 Go/s | 269 Go/s | 336 Go/s | 269 Go/s | 224 Go/s | |
| Fréquence GPU | 947 MHz | 1000 MHz | 863 MHz (base) | 875 MHz (base) | 837 MHz (base) | 1050 MHz (base) | 1126 MHz (base) |
| Fréquence Stream Processors | 947 MHz | 1000 MHz | 863 MHz (base) | 875 MHz (base) | 837 MHz (base) | 1050 MHz (base) | 1126 MHz (base) |
| Fréquence mémoire | 1250 MHz - GDDR5 | 1250 MHz - GDDR5 | 1502 MHz - GDDR5 | 1750 MHz - GDDR5 | 1503 MHz - GDDR5 | 1750 MHz (GDDR5) | 1750 MHz (GDDR5) |
Mise à jour 28 janvier 2015 : Quatre mois après le lancement des GeForce GTX 970, il apparaît que leurs spécifications techniques ont été communiquées de manière erronée à la presse technique (voir NVIDIA évoque les soucis de mémoire sur ses GTX 970 (màj)). Certains utilisateurs ont en effet constaté dans divers jeux des problèmes de performances dès lors que la mémoire vidéo utilisée dépasse les 3,5 Go. Il s'avère finalement que la puce GM204 de la GeForce GTX 970 compte 56 unités ROP, et non 64, que sa taille de mémoire cache L2 tombe à 1,75 Mo (et non 2 Mo) et que son bus mémoire interne opère de manière asymétrique avec 3,5 Go interfacés sur 224 bits et 512 Mo sur 32 bits, ce qui induit une baisse de la bande passante mémoire vidéo de près de 12,5%. En ce sens, la GeForce GTX 970 est en réalité une carte graphique avec bus mémoire 224 bits, et non 256 bits.
Ces nouvelles informations ne changent rien aux performances de la carte qui sont donc identiques à celles que nous évoquions dans notre première publication, puisque les limitations de l'architecture n'ont pas bougées : elles sont juste publiquement connues.On sera toutefois attentif à l'impact éventuel de cette architecture mémoire asymétrique notamment dans les configurations bi-GPU en SLI.
GeForce GTX 980 : la carte
Pour ce test, NVIDIA nous a fait parvenir son design de référence en matière de GeForce GTX 980. Un design de référence désormais bien connu puisqu'il s'agit ni plus ni moins que de celui utilisé pour la GeForce GTX Titan... entre autres. On ne reviendra pas sur les qualités de ce système qui confère aux GeForce d'excellentes propriétés, notamment acoustiques.Pour cette GeForce GTX 980, au format double-slot avec une longueur de 26,5 centimètres, on retrouve sur la tranche un logo GeForce GTX qui s'illumine dès la mise sous tension alors que les languettes SLI sont au programme. Petite nouveauté pour la GeForce GTX 980 : la présence d'une back-plate : une plaque métallique qui recouvre l'arrière du PCB. Cela doit logiquement aider à la dissipation thermique mais aussi participer à la solidité de la carte et plus précisément à sa durabilité. À noter, la présence d'un capot amovible sur cette back-plate : en enlevant une vis on peut ôter une partie métallique censée offrir une meilleure circulation de l'air lorsque deux cartes sont côte à côte, en SLI par exemple. Et pour l'esthétique, sachez que les ailettes du radiateur en aluminium ne sont plus couleur argent mais noires.







L'équerre de cette GeForce GTX 980 évolue avec des ouvertures en forme de triangle et une connectique riche : un seul et unique connecteur DVI mais trois connecteurs DisplayPort et une prise HDMI.
Utilisant l'interface PCI-Express, la carte est alimentée par deux connecteurs 6 broches. NVIDIA évoque un TDP de 165 Watts pour sa carte et les fréquences sont logiquement celles édictées par la marque. En Boost, la carte voit son GPU flirter avec les 1253 MHz.
Gigabyte G1 Gaming : GeForce GTX 980 et GTX 970
Le fabricant Gigabyte a pu nous faire parvenir ses nouvelles cartes graphiques basées sur les nouvelles puces de NVIDIA. Des cartes déjà overclockées.Appartenant à la nouvelle famille G1 Gaming, les deux cartes utilisent le même système de refroidissement maison, à quelques détails près. Gigabyte a en effet fait le choix de ne pas retenir le refroidissement made in NVIDIA, y compris sur sa GeForce GTX 980.
On retrouve sur la GeForce GTX 970, alias GV-N970G1, un radiateur en trois parties : un bloc principal posé sur la puce graphique et les puces mémoire et deux radiateurs annexes reliés au radiateur central par des caloducs en cuivre. Sur sa GeForce GTX 980, la GV-N980G1, Gigabyte a recours à un radiateur différent : plus massif, il est fait de deux blocs. Une large base cuivre recouvre la puce graphique et les puces mémoire alors qu'un second radiateur, connecté au premier via des caloducs, occupe le reste de la longueur de la carte.







Pour refroidir le tout, Gigabyte propose son système WindForce 3X avec trois ventilateurs. Silencieux en fonctionnement, ceux-ci peuvent être relativement bruyants à plein régime, sachez-le. Alors que le bruit est relativement contenu sur le modèle GeForce GTX 970 lors de nos tests en charge, les ventilateurs du modèle GeForce GTX 980 se font entendre... bruyamment. Il faut dire qu'ils tutoient alors les 2900 tours/minute.






Là où NVIDIA a conçu une enveloppe totalement fermée, Gigabyte propose tout l'inverse, avec des cartes dont le carénage est largement ouvert, au risque de donner le sentiment d'une qualité de finition inférieure, avec des câbles électriques qui dépassent à plusieurs endroits. Le système ainsi développé par Gigabyte est aussi plus imposant que celui de NVIDIA : les deux cartes mesurent 30 centimètres de long. Au dos, on retrouve comme pour le modèle de référence de NVIDIA une back-plate tandis que la marque a succombé à une sympathique fantaisie esthétique : un logo « Windforce » s'illumine de bleu sur la tranche des cartes.
L'alimentation s'opère par un connecteur 8 broches et un connecteur 6 broches sur le modèle GeForce GTX 970 tandis qu'il y a deux connecteurs 8 broches sur le modèle GeForce GTX 980. En sortie, les cartes proposent indifféremment trois connecteurs DisplayPort, une prise HDMI et deux prises DVI.
Côté fréquences de fonctionnement, Gigabyte cadence sa GeForce GTX 970 G1 à 1178 MHz avec une fréquence Boost à 1329 MHz. La GeForce GTX 980 G1 va plus loin avec une fréquence de 1228 MHz pour sa puce et un Boost à 1329 MHz. Pour ces deux nouvelles GeForce, Gigabyte cadence la mémoire à 1753 MHz avec 4 Go de GDDR5 à chaque fois.Voici la configuration utilisée pour évaluer les performances de Maxwell et des nouvelles GeForce GTX 970 et 980 :

- Carte mère Asus X99 Deluxe (BIOS 0601),
- Processeur Intel Core i7 5820X,
- 16 Go (4x 4 Go) Mémoire DDR4-2666 Corsair @ 2133,
- SSD Samsung Serie 840 Pro 256 Go
La machine opère sous Windows 8.1 Update 64 bits avec les dernières mises à jour disponibles au moment du test. Côté pilotes nous avons recours aux Catalyst 14.7 bêta et GeForce 344.07. Notez que nous testons nos cartes sur trois résolutions : le classique 1920x1080, le 2560x1600 de notre Dell 30 pouces et le 3840x2160 des nouveaux écrans 4K.
3DMark FireStrike - Extreme
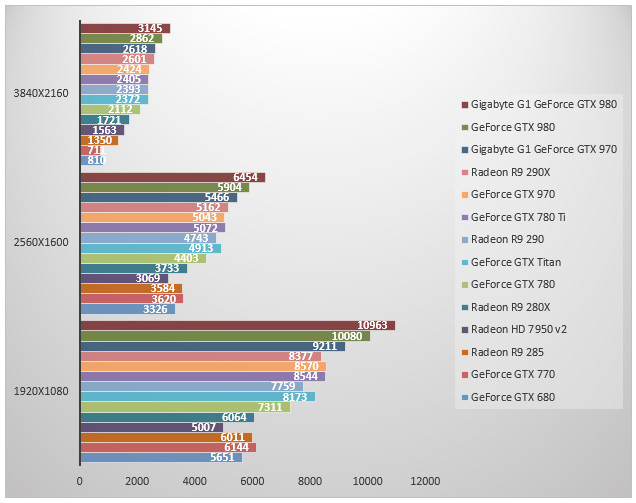
On démarre avec 3DMark où les nouvelles GeForce crèvent le haut du plafond et particulièrement les modèles overclockés de Gigabyte. Ramenée à ses fréquences d'origine, la GeForce GTX 970 se fait légèrement devancer par la Radeon R9 290X. La GeForce GTX 980 reste 14% plus rapide que la Radeon R9 290X. Face à la GeForce GTX 680 le gain de performances est flagrant : 77% en plus pour la GeForce GTX 980 par rapport au GK104.
Dirt Showdown - Ultra - 4x
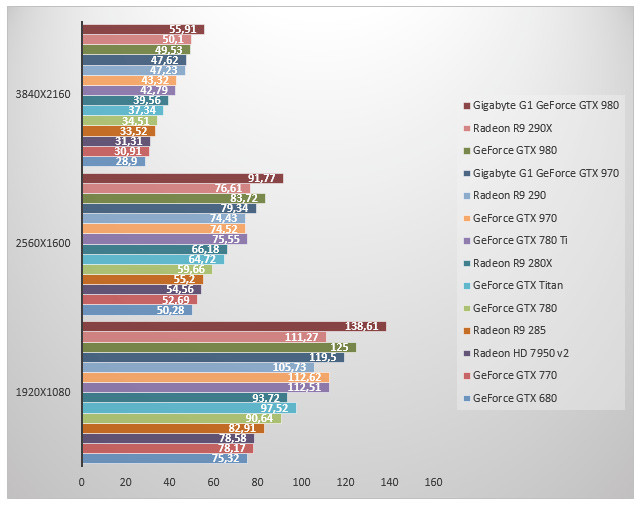
Le jeu de course Dirt, ici testé avec l'illumination globale, place la GeForce GTX 980 de Gigabyte en tête. Ici l'overclocking du taïwanais augmente les performances de 12% face au modèle de référence de NVIDIA. On notera que si la GeForce GTX 980 de référence est nettement devant la Radeon R9 290X en 1080p et en 2560x1600, la tendance s'inverse en 4K où la Radeon R9 290X est plus rapide... d'un demi-cheveu ! L'écart de performances entre GeForce GTX 980 et GeForce GTX 970 est selon Dirt de 10 à 14% selon la résolution. La petite dernière de NVIDIA revendique ici des performances 10% supérieures à la GeForce GTX 780 Ti et l'on ne peut que noter l'écart de performances avec la GeForce GTX Titan.
Batman Arkham Origins - FXAA
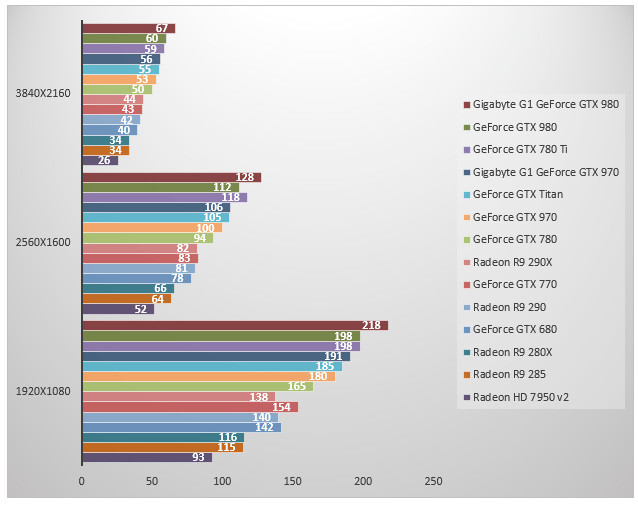
En attendant un nouvel épisode des aventures de l'homme chauve-souris, nous voilà de retour sous Arkham Origins. Pas de grande surprise dans la hiérarchie où la GeForce GTX 980 de Gigabyte est en tête avec des performances 14% supérieures au modèle de base. D'une résolution à l'autre, la GeForce GTX 980 est au même niveau de performances que la GeForce GTX 780 Ti. Face à la GeForce GTX 780, la GeForce GTX 980 est 19% plus rapide. L'écart de performances avec les Radeon est ici conséquent et la GeForce GTX 980 peut se montrer 50% plus rapide que la GeForce GTX 680.
Crysis 3 - Extrême - SMAA 2TX
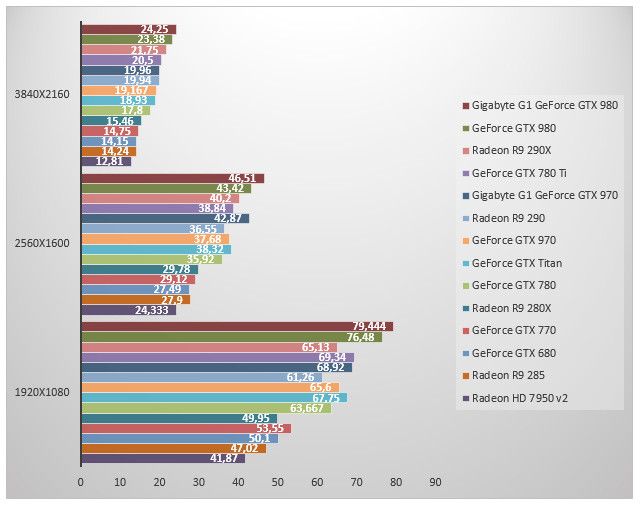
Crysis est testé par le biais de FRAPS au moyen d'une scène reproductible. Les GeForce GTX 980 sont ici en tête devant la Radeon R9 290X qui arrive troisième. Face à la GeForce GTX 780 Ti, la nouvelle référence Maxwell est 12% plus rapide en 2560x1600. Un écart qui atteint 21% si l'on compare Maxwell au Big Kepler de la GeForce GTX 780 (modèle non Ti donc). Face à une Radeon HD 7950 v2, NVIDIA affiche aavec sa GeForce GTX 970 des performances 55% supérieures en 2560x1600.
Bioshock Infinite - Ultra DDOF
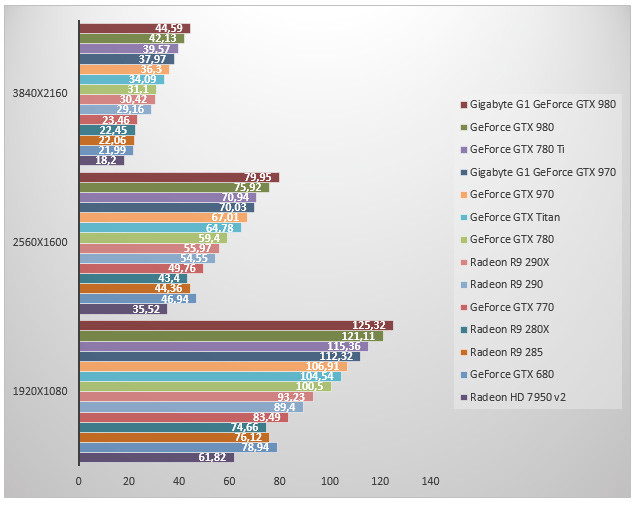
Autre jeu utilisant l'Unreal Engine, Bioshock Infinite place les GeForce GTX 980 en tête. Les bienfaits de l'overclocking de Gigabyte sont limités : 5% en 2560x1600. Face à une GeForce GTX 780, la GeForce GTX 980 est 28% plus rapide. L'écart de performances entre GeForce GTX 980 et GeForce GTX 970 est ici de 13% du moins en 2650x1600. Face à une Radeon R9 290, la GeForce GTX 970 est 19% plus rapide en 1920x1080.
Battlefield 4 - Ultra - AA 4x
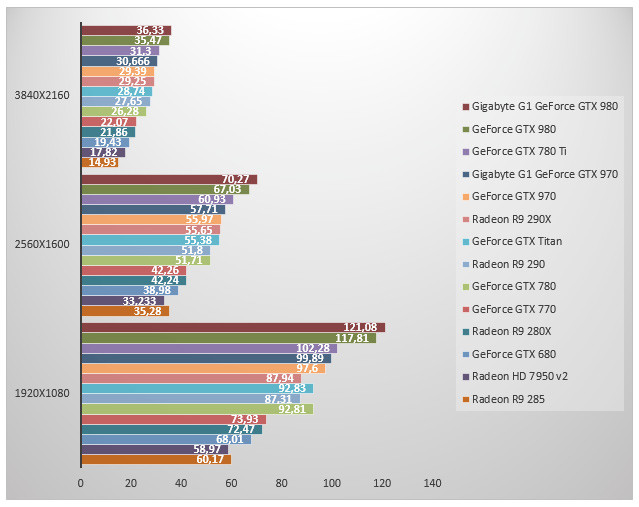
Battlefield 4 est l'autre jeu de notre sélection que nous testons par le biais de FRAPS via une scène que nous reproduisons à l'identique trois fois de suite. Pas de surprise ici. Les GeForce GTX 980 dominent et le modèle de référence est 10% plus rapide que la GeForce GTX 780 Ti et 21% plus rapide que la GeForce GTX Titan en 2560x1600. Face à notre brave GeForce GTX 680, la GeForce GTX 970 est 43% plus rapide alors que la GeForce GTX 980 est près de 71% plus rapide en 2560x1600.
Unigine 4.0 - High - Normal - 4x
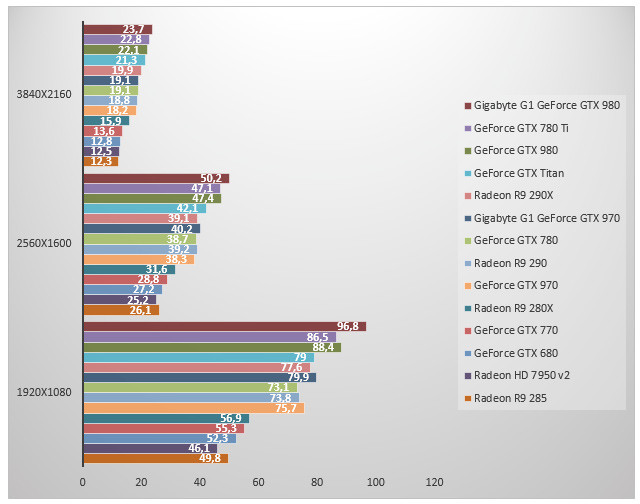
Unigine est un test synthétique qui vise avant tout à évaluer les performances géométriques de nos cartes. On note qu'en 4K, les performances sont très proches, bien que la hiérarchie jusqu'à présent constatée soit maintenue intacte. En 2560x1600, on observe que GeForce GTX 980 et GeForce GTX 780 Ti sont à égalité tandis que la GeForce GTX 980 est 12% plus rapide que la GeForce GTX Titan. Face à la GeForce GTX 680, la GeForce GTX 980 est 74% plus rapide. Face à la Radeon R9 290X, le gain de performances pour la GeForce GTX 980 est de 21%.
Hitman Absolution - Ultra - FXAA - AF 16x
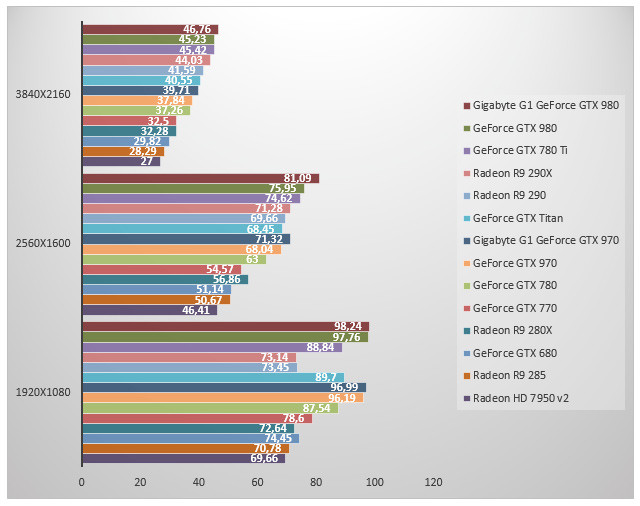
On termine avec l'agent 47. GeForce GTX 980 et GeForce GTX 780 Ti sont en tête. La Radeon R9 290X ne démérite pas tandis que l'écart entre GeForce GTX 980 et GeForce GTX 970 est ici de 11%. Face à la GeForce GTX 780 (modèle non Ti), la GeForce GTX 980 est 20% plus rapide en 2560x1600.
Consommation
Nous avons bien sûr vérifié la consommation électrique de ces nouvelles GeForce. Pour ce faire, nous mesurons la consommation électrique globale de la machine au moyen d'un wattmètre. La consommation est mesurée à la prise, avec deux relevés : au repos sur le bureau Windows, puis en charge lors d'un 3DMark 11 plutôt intensif en 2560x1600.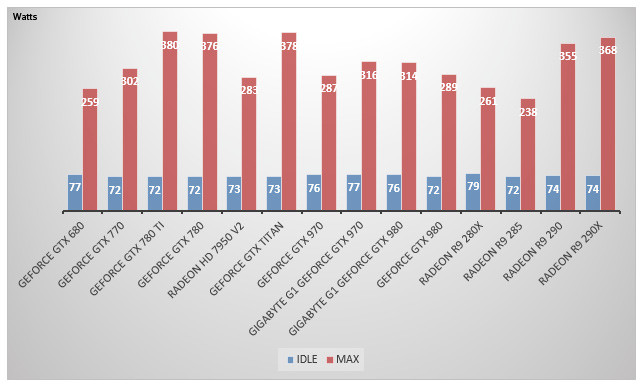
Au repos, pas de surprise : notre système oscille autour des 72 Watts quelle que soit la carte graphique. En charge, la consommation de notre système en GeForce GTX 980 s'établit à 289 Watts, pratiquement une centaine de watts de moins que pour notre machine en GeForce GTX 780 Ti ! Cela place la consommation au même niveau que celle relevée avec une Radeon HD 7950 v2. Face à une Radeon R9 290 ou 290x on gagne pas loin de 60 Watts sur la consommation totale du système. Quant à l'écart entre GeForce GTX 970 et 980 il est ici ténu : une poignée de watts tout au plus.
Conclusion
Arrivés au terme de ce test, il apparaît comme évident que les nouvelles GeForce de NVIDIA ont de solides atouts pour convaincre. Si nous attendions de longue date le renouvellement de l'offre haut de gamme de la marque au caméléon, NVIDIA nous propose avec ses GeForce 900 ce qui apparaît comme une nouvelle référence en matière de performances par watt.En survolant rapidement notre dossier, certains pourraient toutefois regretter que les performances de la GeForce GTX 980 ne soient pas significativement supérieures à celles de la GeForce GTX 780 Ti. L'occasion pour nous de clarifier un point important : la GeForce GTX 980 n'est pas un modèle Ti, elle vise avant tout à remplacer la vénérable GeForce GTX 680 et sa puce GK104. On pourrait se dire que NVIDIA a conçu la GeForce GTX 980 pour remplacer la GeForce GTX 780 mais ce ne serait pas tout à fait exact : la GeForce GTX 780 utilise une puce GK110 bien plus massive et complexe (~7 Milliards de transistors) que le GM204 (~5 Milliards de transistors) des nouvelles GeForce GTX 980. Maxwell fait en effet son entrée sur le haut de gamme avec une version modérée de son architecture. Nul doute que NVIDIA pourra sortir l'artillerie lourde avec une version plus massive de Maxwell pour d'éventuelles Titan II ou GeForce GTX 980 Ti, au risque bien sûr de dégrader l'efficacité énergétique.

En attendant, les choix opérés par les équipes d'ingénierie de NVIDIA s'avèrent payants, car si l'architecture Maxwell n'est pas un bouleversement par rapport à l'existant, elle s'affiche comme très équilibrée. Les performances sont au rendez-vous et la consommation limitée est assez appréciable. La GeForce GTX 980 représente pour l'heure la solution la plus avancée dans la famille Maxwell, tandis que la GeForce GTX 970, plus modeste, ne démérite pas, loin s'en faut. En face, les Radeon R9 peuvent difficilement convaincre : alors que leurs performances sont remises en cause, la consommation des cartes AMD semble d'un coup très élevée.

Une inconnue subsiste : savoir si le stock au lancement sera au rendez-vous et si les partenaires de NVIDIA suivront le tarif recommandé. Il se pourrait fort que certains grands noms taïwanais facturent leurs cartes plus chères.

Quant aux modèles de Gigabyte ils sont franchement convaincants de par leurs performances. Leur overclocking booste encore les très bons scores de Maxwell alors que le système de refroidissement nous laisse plus circonspects. Le refroidissement de la GeForce GTX 970 G1 nous semble correctement conçu. Toutefois celui de la GeForce GTX 980 G1 se montre rapidement bruyant dès que l'on charge un peu la mule. Et si le GPU semble mieux refroidi que sur le design de référence de NVIDIA, cela se fait au détriment du confort d'utilisation. Pour un peu, on aurait préféré que Gigabyte conserve le système de refroidissement de référence de NVIDIA, autrement plus convaincant.
Télécharger DirectX pour Windows.








