

Une puce graphique qui se veut bien plus efficace que celles de la précédente génération, dont la consommation était l'un des défauts majeurs, notamment dans le domaine de l'ordinateur portable. Le caméléon a donc taché de rendre bien moins gourmandes ses puces avec un objectif très clair : asseoir sa suprématie sur ce marché en constante progression, puisque selon le constructeur, ses puces sont présentes dans près de 60% des 75 millions d'unités vendues l'année dernière dans le monde (source : Mercury).
Pour ce faire, NVIDIA se devait de suivre la nouvelle tendance du marché, insufflée par Intel. Vous l'aurez compris, les nouvelles puces du caméléon doivent équiper des ultrabooks, comme le Acer Aspire M3, que nous testions récemment, avec toutes les contraintes que cela impose, notamment en matière énergétique. Un GPU dédié dans un ultrabook ? C'est tout sauf une surprise, puisque Samsung avait déjà initié ce mouvement avec son Series 5 Ultra, un ultrabook de 14 pouces doté d'un AMD Radeon HD 7550M.
Nous ne reviendrons pas sur cette notion d'ultrabook, que nous avons largement abordée au cours des précédents tests. Mais une chose est certaine : l'ordinateur portable devient plus fin et moins encombrant, et pour continuer d'exister sur ce marché, NVIDIA se devait de suivre le mouvement. Comment le caméléon a-t-il relevé ce défi ? Comment se compose la gamme de ses nouvelles GeForce 600M ? Et enfin, quelles sont les performances de la première d'entre elles, le GeForce GT 640M ? Place aux réponses !

Kepler, les rappels
Nous ne reviendrons pas en détail sur l'architecture Kepler, Julien ayant déjà fait tout le travail dans son test du GeForce GTX 680. Quelques rappels s'imposent simplement. Kepler est une sorte de Fermi de troisième génération, puisque NVIDIA a basé son travail d'optimisation sur sa précédente architecture. On retrouve donc une puce divisée en GPC (pour Graphics Processing Cluster), mais l'agencement de ces derniers évolue. Les SM (ou Streaming Multiprocessors) font ainsi place au SMX, et lorsque l'on trouvait 4 SM par GPC sur Fermi, Kepler ne compte plus que 2 SMX.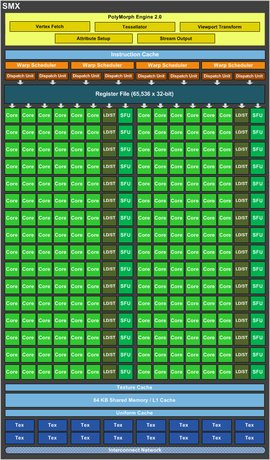
Il ne s'agit évidemment pas d'une simple division par deux des unités de calculs, puisque la structure du SMX diffère de celle du SM. De 48 cœurs CUDA dont pouvait disposer un SM sur une puce de la famille des GeForce 500M, on passe ici à 192 cœurs CUDA par SMX. Sachez que chacun de ces SMX embarque 16 unités de texture, les deux SMX disposant d'un total de 8 unités ROPS.
Un simple réagencement donc, mais qui n'est pas sans conséquence : NVIDIA abandonne le système de double cadencement, et la fréquence de fonctionnement des cœurs CUDA devient ainsi identique à celles des processeurs de flux sur Kepler. L'objectif est simple : conserver des performances équivalentes pour une consommation significativement moindre : NVIDIA avance que Kepler propose un ratio performance / watt deux fois plus important que Fermi.

L'autre modification significative de Kepler concerne la mémoire. Le bus 256 bits, qui existait sur certaines puces, fait place au 128 bits, puisque la puce est équipée d'un contrôleur mémoire de 64 bits par SMX. Pour un GPC proposant deux SMX, on a donc affaire à un bus mémoire de 128 bits. En revanche, ces contrôleurs ont le bon gout de prendre en charge de la mémoire plus véloce, fonctionnant à 1 000 MHz (pour une fréquence totale de 4 GHz). Une hausse significative de la fréquence de la mémoire qui compensera la diminution du bus mémoire... si tant est que la puce mobile soit équipée de mémoire GDDR5, ce qui n'est pas toujours le cas, loin s'en faut.
Parmi les autres nouveautés introduites par Kepler, nous pourrions évoquer le GPU Boost, un mélange de solutions matérielle et logicielle visant à optimiser la carte pour en tirer le meilleur, notamment en ce qui concerne les fréquences de fonctionnement. Nous nous arrêterons ici pour les détails, puisque les puces mobiles de génération Kepler ne bénéficient tout simplement pas de cette technologie.
De même, nous n'avons pas pu étrenner les pilotes de la série 300 sur notre GeForce GT 640M de test : les puces mobiles de la série 600M ne bénéficient donc pas pour le moment des nouvelles subtilités en matière de traitement d'image (FXAA, Adaptative VSync) ou d'encodeur (NVENC), dont vous pourrez retrouver les détails dans l'article du GTX 580M. Toutefois, NVIDIA nous précise que les pilotes unifiés devraient faire leur apparition le 2 avril prochain.

Adaptative VSync et FXAA, bientôt sur les puces mobiles ?
Kepler, oui, mais pas pour tout le monde
Comme souvent avec NVIDIA, il faut un peu se bagarrer avec les spécifications pour extraire l'information intéressante. Qui peut se résumer ici en une phrase : à l'heure actuelle, Kepler concerne seulement trois, voire quatre puces graphiques parmi la nouvelle gamme présentée. Pour les autres, nous avons le droit au désormais classique renommage, comme nous allons le voir.| Caractéristiques | ||||||||||
| Puce | Finesse (nm) | Coeurs CUDA | Fréq. des coeurs (MHz) | Fréq. des proc. de flux (MHz) | Type de mémoire | Quantité de mém. (Mo) | Bus (bits) | Fréq. mém. (MHz) | Bande pass. (Gb/s) | |
| GT 520MX | GF 119 | 40 | 48 | 900 | 1 800 | DDR3 | 1 024 | 64 | 1 800 | 14,4 |
| GT 610M | GF 119 | 40 | 48 | 900 | 1 800 | DDR3 | 2 048 | 64 | 1 800 | 14,4 |
| GT 525M | GF 108 | 40 | 96 | 600 | 1 200 | DDR3 | 1 024 | 128 | 1 800 | 28,8 |
| GT 620M | GF 117 | 28 | 96 | 625 | 1 250 | DDR3 | 1 024 | 128 | 1 800 | 28,8 |
| GT 540M | GF 108 | 40 | 96 | 672 | 1 344 | DDR3 | 1 024 | 128 | 1 800 | 28,8 |
On commence avec les puces les moins véloces et cette GT 610M qui n'est autre que le GT 520MX. Comme vous pouvez le voir, rien ne change, et nous avons bien affaire à une puce de génération Fermi (GF 119). Le GT 620M représente quant à lui une petite évolution, puisque le GF 117 utilise des puces TSMC en 28 nm et non plus en 40 nm. En revanche, on retrouve bien les 96 cœurs CUDA des GT 525M et GT 540M, seules les fréquences de fonctionnement de ces cœurs différenciant ces trois puces.
| Caractéristiques | ||||||||||
| Puce | Finesse (nm) | Coeurs CUDA | Fréq. des coeurs (MHz) | Fréq. des proc. de flux (MHz) | Type de mémoire | Quantité de mém. (Mo) | Bus (bits) | Fréq. mém. (MHz) | Bande pass. (Gb/s) | |
| GT 550M | GF 108 | 40 | 96 | 740 | 1 480 | DDR3 | 1 024 | 128 | 1 800 | 28,8 |
| GT 630M | GF117 GF 108 | 28 40 | 96 | 800 | 1 600 | DDR3 | 2 048 | 128 | 2 000 | 32,0 |
| GT 555M | GF108 | 40 | 96 | 753 | 1 506 | GDDR5 | 1 024 | 128 | 3 138 | 50,2 |
| GT 635M | GF 116 | 40 | 96 | 753 | 1 506 | GDDR5 | 2 048 | 192 | 1 800 | 43,2 |
| GT 555M | GF 106 | 40 | 144 | 590 650 | 1 180 1 300 | DDR3 | 1 536 2 048 | 192 128 | 1 800 | 43,2 28,8 |
| GT 635M | GF 116 | 40 | 144 | 675 | 1 350 | DDR3 | 2 048 | 192 | 1 800 | 43,2 |
| GT 640M | GK 107 | 28 | 384 | 625 | 625 | DDR3 / GDDR5 | 2 048 | 128 | 1 800 / 4 000 | 28,8 / 64,0 |
| GT 640M LE | GK 107 | 28 | 384 | 500 | 500 | DDR3 | 2 048 | 128 | 1 800 | 28,8 |
| GT 640M LE | GF 108 | 40 | 96 | 762 | 1 524 | DDR3 / GDDR5 | 2 048 | 128 | 1 800 / 3 138 | 28,8 / 50,2 |
En ce qui concerne les puces de milieu de gamme, c'est encore plus complexe. A l'image de ce qui existe sur le GT 620M, le GT 630M bénéficie également des puces TSMC en 28 nm.... mais pas toujours ! Et si vous trouviez que le nombre de versions différentes du GT 555M était trop important, pas de panique : le GT 635M prend sa place, avec là aussi plusieurs versions aux profils assez différents.
Finalement, la première puce à proposer l'architecture Kepler n'est autre que le GT 640M que nous testons aujourd'hui. Elle est basée sur un GK 107 qui est peu ou prou un quart de GK 104, qui équipe la puce desktop GTX 680. Notez que cette puce dispose de deux variantes « LE », dont l'une est identique, fréquence de fonctionnement des cœurs mise à part, tandis que l'autre est basée sur un GF 108. Et on vous épargne les versions DDR3 ou GDDR5... Puisqu'on vous dit que c'est simple ! Plus sérieusement, on constate que NVIDIA propose aux OEM un très grand nombre de puces pour mieux s'introduire dans leurs modèles, au détriment de la clarté de son offre pour les consommateurs finaux.
| Caractéristiques | ||||||||||
| Puce | Finesse (nm) | Coeurs CUDA | Fréq. des coeurs (MHz) | Fréq. des proc. de flux (MHz) | Type de mémoire | Quantité de mém. (Mo) | Bus (bits) | Fréq. mém. (MHz) | Bande pass. (Gb/s) | |
| GT 650M | GK 107 | 28 | 384 | 850 735 | 850 735 | DDR3 GDDR5 | 2 048 | 128 | 1 800 4 000 | 28,8 64,0 |
| GTX 660M | GK 107 | 28 | 384 | 835 | 835 | GDDR5 | 2 048 | 128 | 4 000 | 64,0 |
| GTX 670M | GF 114 | 40 | 336 | 598 | 1 196 | GDDR5 | 3 072 | 192 | 3 000 | 72,0 |
| GTX 580M | GF 114 | 40 | 384 | 620 | 1 240 | GDDR5 | 2 048 | 256 | 3 000 | 96,0 |
| GTX 675M | GF 114 | 40 | 384 | 620 | 1 240 | GDDR5 | 2 048 | 256 | 3 000 | 96,0 |
Et on termine par le haut de gamme de chez NVIDIA, où GT 650M et GTX 660M constituent les deux nouveautés, puisqu'elles seules sont basées sur l'architecture Kepler. Notez que si l'une des deux versions du GT 650M voit la fréquence de ses cœurs CUDA dépasser celles de la GTX 660M (850 MHz contre 835), le type de mémoire utilisé est différent, offrant au GTX 660M un très net avantage.
Notez que le GTX 675M est un simple renommage du GTX 580M... en attendant le GTX 680M avec l'architecture Kepler ? Enfin, comprenez bien que toutes les caractéristiques techniques données dans ces tableaux sont les spécifications maximales de NVIDIA ; les constructeurs peuvent tout à fait revoir à la baisse les fréquences des unités de calculs et / ou de la mémoire, notamment.
Toutes ces puces sont compatibles avec la technologie Optimus selon NVIDIA, et supportent toutes DirectX 11 (et même 11.1 pour les puces Kepler), CUDA, OpenCL.3D Vision et 3DTV Play sont également de la partie, sauf pour les 610M et 620M.La promesse de NVIDIA avec son Kepler : un rendement, ou rapport performance / watt, deux fois plus important que sur la série 500M. Pour vérifier ces performances, nous avons confronté le GT 640M à divers titres du moment, comme au traditionnel 3DMark Vantage. Nous avons utilisé les derniers pilotes en date pour les GPU mobiles (série 261), tandis que nos machines fonctionnaient sous Windows 7 Service Pack 1 en 64 bits.
Configuration de test

Notez que notre GT 640M de test est équipé de 1 Go de DDR3 tandis que ses processeurs de flux fonctionnent à... impossible de le savoir ! En effet, les informations fournies par les drivers NVIDIA ne sont pas correctes, et comme les GPU-Z et autres logiciels de ce type se basent sur ces informations, impossible pour nous de savoir si notre puce fonctionne bien aux 625 MHz que préconise NVIDIA. De même, NVIDIA évoque un éventuel système de régulation des fréquences (qui est tout autre que le GPU Boost), sans que nous puissions en vérifier ni l'existence, ni le fonctionnement.
Sachez également que faute de plate-forme adéquate, nous ne pouvons faire figurer de puces AMD sur ces graphiques. Nous mettrons à jour ce test dès que nous aurons d'autres résultats à vous fournir.
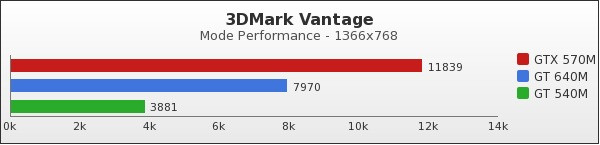
Sous 3DMark Vantage, le GT 640M se place entre les deux autres puces NVIDIA, très loin devant le GT 540M qu'il est amené à remplacer sur le marché du milieu de gamme.

Call of Duty 4 : Modern Warfare met le GT 640M dans la même position que 3DMark, à savoir à mi-chemin entre un GT 540M et un GTX 570M. Nous avons ici utilisé une séquence enregistrée par nos soins et désactivé l'anti-aliasing.

Sous Mafia II, le GTX 570M se détache nettement, mais rappelons qu'il est aidé par un processeur plus véloce que celui qui équipe l'ultrabook d'Acer. Sur ce test, nous avons opté pour un réglage « Elevé », et l'AF est placé sur 16x et l'AA est désactivé sur le test comparatif (avec les deux autres puces), puis activé (score en bas du graphique). Le GT 640M réalise alors un score légèrement supérieur à celui du GT 540M, sans anti-aliasing.
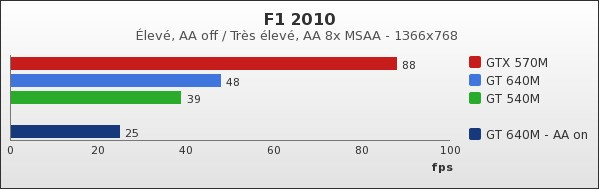
Avec F1 2010, le score du GT 640M est là aussi relativement proche de celui du GT 540M, bien que supérieur. Le GTX 570M est quant à lui loin devant. Lorsque l'anti-aliasing passe à 8x en MSAA, le GT 640M peine alors à afficher un jeu jouable, avec des réglages placés sur « Très élevés » toutefois.
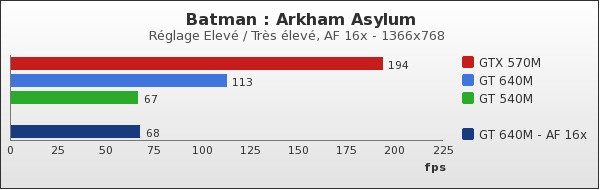
Sur le classique Batman : Arkham Asylum, les performances du GT 640M sont quasiment deux fois supérieures à celles du GT 540M. Et lorsque l'on passe du réglage « Elevé » à « Très élevé » (en activant l'AF 16x), le score du GT 640M égale celui du GT 540M. Si l'on peut déjà jouer à Batman avec le GT 540M, avec son successeur, on peut accroitre significativement la qualité de l'image sans détériorer les performances.
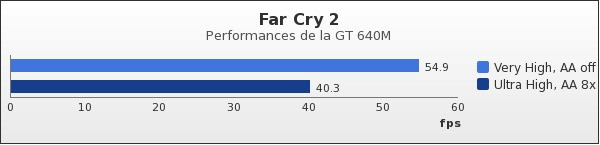
Pour les jeux suivants, nous n'avons malheureusement pas de moyen de comparaison avec d'autres puces mobiles. En revanche, nous avons joué avec les paramètres de qualité d'image (niveau de détails, AA, AF) pour évaluer les performances du GT 640M. Sous Far Cry 2, même lorsque l'on passe en mode « Très élevé » et AA 8x, on passe la barre des 40 FPS.

Sous F1 2011 en revanche, mieux vaut conserver un niveau de détail raisonnable : le passage en Ultra et AA 8x MSAA fait chuter le score de moitié, et les 22 FPS réalisés ne permettent pas de jouer dans des conditions convenables.
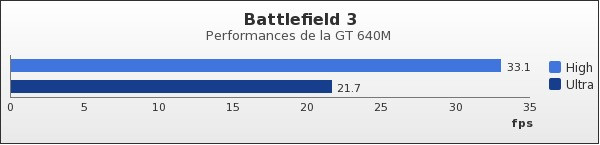
Passons au très prisé Battlefield 3, qui donne un score supérieur à 30 FPS en mode « Elevé ». Comme sous F1 2011, le passage à un niveau de détail plus important pèse de façon trop importante sur les performances.
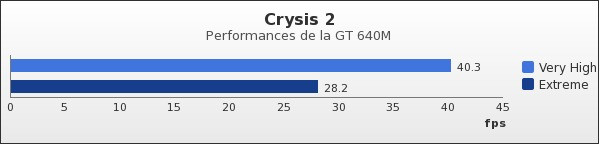
Terminons par Crysis 2, muni du patch 1.9, des textures HR et en mode DirectX 11. Belle performance du GT 640M sur ce jeu, puisque même en mode Extreme, la puce de NVIDIA parvient à taquiner les 30 FPS.
Températures et consommation
Si les performances sont clairement en hausse par rapport au GT 540M, qu'en est-il de la consommation, de l'échauffement ou des nuisances sonores, trois éléments importants sur un portable comme un ultrabook ? Concernant la température, pas d'inquiétude : la sonde de la puce graphique n'a pas indiqué de chiffre excédant les 75°C, alors qu'au repos, la puce se stabilisait à 50°C. Une température relativement faible qui va de pair avec une ventilation bruyante ? Pas au repos, puisque de 34,5 dB(A), la pression acoustique de notre pièce n'est passée qu'à 36,1 dB(A). Merci Optimus ! En charge en revanche, l'Aspire M3 d'Acer se fait clairement entendre, avec une pression acoustique mesurée à 48,3 dB(A).Pour ce qui est de la consommation, difficile de mesurer cette grandeur pour une puce graphique mobile. Nous avons toutefois relevé la consommation totale de la machine alors que processeur et puce graphique étaient en pleine charge. Quel que soit l'effort demandé à la puce mobile (affichage sur 768 ou 1 080 lignes), la consommation du portable n'a pas excédé 47 Watts.

Louons enfin la technologie Optimus du caméléon : au repos, l'Acer Aspire M3 voit sa consommation chuter à moins de 9 Watts, signe que le HD 3000 du processeur prend bien la main sur le GPU dédié, qui ne grève en rien l'autonomie de cet ultrabook, que nous testions il y a quelques jours.
Conclusion
Lors de la conférence de présentation de son Kepler, NVIDIA a clairement axé sa communication autour du rapport performance / watt de ses nouvelles puces. L'on pouvait alors craindre que les performances n'évolueraient guère par rapport à la génération Fermi, le constructeur privilégiant une diminution drastique de la consommation, afin de faire rentrer ses puces dans ce qui représente la nouvelle génération d'ordinateurs portables, à savoir les ultrabooks.
Heureusement, il n'en est rien, et le GT 640M offre des performances tout à fait remarquables et bien supérieures à celles du GT 540M qu'elle est amenée à remplacer sur le segment du milieu de gamme. Au final, avec cette génération de puces, on parvient à obtenir des ordinateurs portables à la fois fins et polyvalents, pour lesquels performances et autonomie ne sont plus antinomiques. Si l'on considère que le caméléon est parvenu à établir des partenariats avec tous les plus grands constructeurs de portables (Asus, Dell, Lenovo, Toshiba, Samsung, HP, Acer, Sony et MSI), il y a fort à parier de voir cette puce inonder le marché comme l'a fait le GT 540M à son époque, voire même davantage.
Un petit bémol toutefois : l'absence de pilotes compatibles et l'opacité qui en résulte sur les fréquences de fonctionnement ou un hypothétique mécanisme de régulation de ces dernières nous chagrinent quelque peu. Impossible de connaître exactement ce que l'on teste : c'est tout à fait dommage ! Nous reviendrons évidemment sur le sujet dès la mise à disposition des pilotes par NVIDIA.

Reste à savoir comment réagira la concurrence à l'alliance de ces nouvelles puces mobiles et à celle des processeurs Intel Ivy Bridge : AMD ne devrait pas trop tarder à proposer son Trinity, l'architecture appelée à succéder à Llano. Nous verrons si cela pourra ou non constituer une alternative intéressante dans le segment des ultrabooks.
En Bonus, découvrez GeForce GTX 880M : la puce mobile de NVIDIA basé sur Kepler








