

NVIDIA semble enfin prêt à nous proposer la relève de Fermi, puisque la marque annonce aujourd'hui Kepler. Kepler, c'est d'abord le nom d'un fameux astronome, mais c'est aussi le nom de code de la nouvelle architecture graphique de la firme de Santa-Clara, une architecture qui va faire ses premiers pas sur le marché avec un vaisseau amiral flambant neuf sous les traits du GeForce GTX 680.
Alors qu'AMD a quelque peu coupé l'herbe sous le pied de NVIDIA en matière d'annonces technologiques, les Radeon HD 7000 enchainant les premières qu'il s'agisse de DirectX 11.1, de PCI-Express 3.0 ou encore de gravure en 28nm, la marque en sera-t-elle réduite à jouer le moi aussi pour ses GeForce 600 ? Rien n'est moins sûr !
Quant à la philosophie derrière la nouvelle GeForce GTX 680, nouveau porte-étendard de NVIDIA, il faut retenir trois piliers de développement : plus rapide, plus fluide et plus riche ! La conjugaison de ces trois axiomes permettant à NVIDIA d'affirmer que la puce GeForce GTX 680 est la plus efficace jamais développée. Voyons cela !

Kepler : Fermi passe la seconde !
L'architecture Kepler est, et NVIDIA ne s'en cache pas, une évolution de Fermi. Lorsqu'en 2010, NVIDIA lançait l'architecture Fermi, la firme allait dans le sens d'un plus grand parallélisme et ce, y compris pour les tâches géométriques comme la tesselation ou le displacement mapping. Fermi était également l'occasion pour NVIDIA de faire progresser les capacités de sa puce en matière de calcul généraliste, notamment via des changements de contexte plus rapides. Le but numéro un ayant présidé à la conception de Kepler aura été d'optimiser le fameux ratio performance par watt en faisant en sorte que l'architecture délivre le maximum de performances pour une consommation la plus faible possible.En s'attardant sur l'architecture Kepler à un haut niveau, on observe un découpage similaire à Fermi. On retrouve en effet une puce toujours organisée selon quatre GPC ou Graphics Processing Cluster, chaque GPC contenant diverses unités spécialisées.
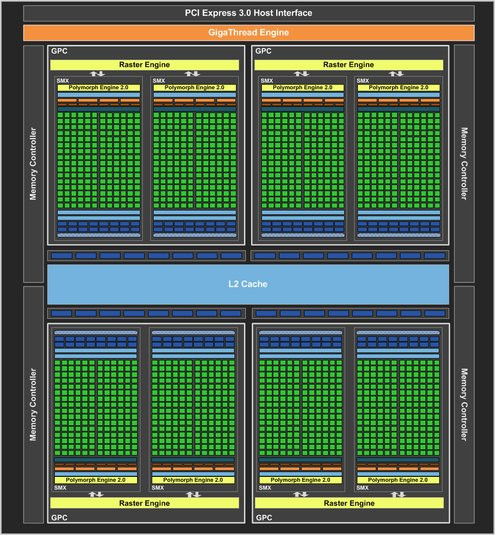
Diagramme de l'architecture Kepler
Si la notion de GPC perdure, chaque GPC étant toujours dotée de son propre moteur de rasterisation, l'agencement évolue. Avec Fermi, on retrouvait dans chaque GPC quatre blocs dits SM ou Streaming Multiprocessors, contenant nos fameux cœurs CUDA. Avec Kepler, la notion de SM évolue pour devenir SMX. Le bloc SMX renferme toujours les cœurs d'exécution CUDA amenés à travailler sur nos instructions de shading et tandis que Fermi comptait quatre SM par GPC, Kepler fait avec deux SMX par GPC.
Il s'agit ici avant tout de réorganiser les ressources de calcul de la puce en vue d'optimiser le rendement de l'architecture puisque s'ils sont moins nombreux, les blocs SMX sont évidemment plus garnis en unités de calcul. Rappelons du reste qu'un bloc SMX (comme un SM en son temps) renferme tout à la fois les cœurs CUDA, mais également le moteur géométrique ou encore nos unités de texture. Un simple bloc SMX peut donc travailler aussi bien sur des pixels, des textures, des calculs génériques ou même des simulations de rendu physique.
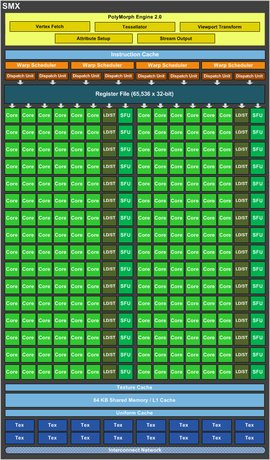
Gros plan sur un SMX
Dans sa version la plus évoluée, l'architecture Kepler, qui est dorénavant compatible DirectX 11.1, peut proposer jusqu'à 192 coeurs CUDA par SMX contre 32 pour les SM de Fermi. La contrepartie, car contrepartie il y a bel et bien, c'est que NVIDIA abandonne le système de double cadencement de ses précédentes GeForce. Souvenez-vous avec le GeForce GTX 480 par exemple, l'ensemble des blocs de la puce graphique opérait à une fréquence de base, mais cette fréquence était deux fois supérieure pour les unités de calcul CUDA. Cela avait pu conférer un avantage certain au caméléon à l'époque du G80 et consorts, mais depuis cela s'était peut-être transformé en handicap flagrant notamment en terme de consommation ou d'efficacité énergétique.

Changement au niveau des domaines de fréquence de Kepler
Du coup grâce à cet artifice, NVIDIA réussit à proposer plus de cœurs CUDA tout en ne faisant pas exploser la consommation améliorant ainsi mécaniquement le ratio performance par watt. NVIDIA table ici sur un rapport performance par watt deux fois supérieur à Fermi.
Kepler plus en détails
Avec 192 noyaux CUDA par SMX et un total de huit SMX pour la puce, NVIDIA peut se vanter d'aligner la bagatelle de 1 536 noyaux CUDA dans sa GeForce GTX 680. Tout de même. En terme d'efficacité, NVIDIA dit avoir à minima maintenu le débit des opérations mathématiques par cycle d'horloge face au GeForce GTX 580, alors qu'il a été amélioré pour certaines opérations clés (FMA32, opérations prises en charge par les SFU ou Special Function Unit, etc). Pour soutenir nos unités CUDA, la puce propose toujours deux niveaux de mémoire cache. Chaque SMX dispose ainsi de 64 Ko de mémoire partagée, alors que la puce est dotée d'un second niveau de mémoire cache. On retrouve ainsi 512 Ko de mémoire cache L2, avec un débit revu à la hausse par rapport à Fermi.Pour piloter tout ce petit monde, chaque SMX embarque quatre schedulers, chacun capable d'envoyer deux instructions par cycle d'horloge et par warp. Le concept des schedulers n'est pas nouveau puisqu'il permet de s'assurer de la pleine utilisation des unités de calcul en répartissant la charge de travail au mieux entre celles-ci. En revanche, ce qui est nouveau, c'est l'optimisation apportée par NVIDIA, toujours dans un but de meilleure efficacité énergétique.
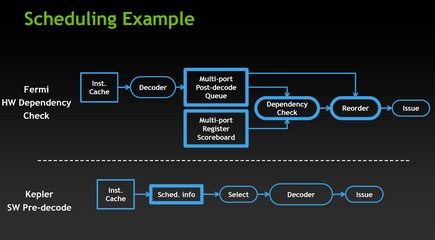
Des changements au niveau du scheduling
Concrètement, certaines unités matérielles présentes au cœur de Fermi ont été rationalisées avec Kepler. Elle servaient notamment à identifier les instructions prêtes en fonction de leurs dépendances. C'est maintenant le compilateur qui va déterminer en amont quand les instructions seront effectivement prêtes, ce qui se traduit au niveau de la puce par la suppression de divers blocs matériels complexes et gourmands en énergie. Kepler ne comporte plus qu'un seul bloc matériel en charge d'extraire les informations prédéterminées au niveau des temps de latence pour déterminer l'éligibilité des flux de données à traiter. La conséquence de ce changement, c'est que le compilateur des pilotes NVIDIA pourra probablement faire l'objet d'optimisations dans les semaines et mois à venir avec une incidence directe sur les performances.
Kepler, les textures, la géométrie et la mémoire
Nous l'évoquions, les blocs SMX ne renferment pas que les fameux cœurs CUDA. On retrouve également les unités de texture. Face à Fermi, leur nombre évolue sensiblement tout comme leur agencement qui s'adapte pour ainsi dire mécaniquement, afin de suivre le passage de SM à SMX. Quand chaque SM de Fermi comptait 4 unités de texture, chaque SMX de Kepler en embarque 16. Avec deux SMX par GPC, la petite dernière de NVIDIA dispose donc de 128 unités de texture contre 64 pour la GeForce GTX 580. NVIDIA en profite pour introduire les Bindless Textures, un mécanisme qui permet à un shader de référencer directement les textures en mémoire sans passer par un tableau limité à 128 entrées.
Kepler et les bindless textures
Dotée de deux fois plus d'unités de texture que Fermi, Kepler n'est en revanche pas aussi bien loti lorsque l'on considère le nombre d'unités ROP, ces unités en charge des dernières opérations de traitement de nos pixels comme l'anticrénelage par exemple. On n'en compte plus que 32 au total, chaque moteur de rasterisation de nos GPC contenant huit unités ROP capables de traiter individuellement un échantillon de couleur.
En matière de géométrie, les Polymorph Engine ou moteurs polymorphes passent en version 2.0. Présents au cœur de chaque SMX, ils regroupent diverses fonctions, dont le moteur de tesselation. NVIDIA indique avoir doublé les performances tant en matière de traitement des primitives que de tesselation par rapport à Fermi. Mais quand le GeForce GTX 580 comptait 16 moteurs polymorphes, le GeForce GTX 680 n'en a plus que 8. Toutefois, vu que leur performance a été doublée et considérant la fréquence de fonctionnement supérieure de Kepler face à Fermi, ce nombre ne devrait pas constituer un handicap.
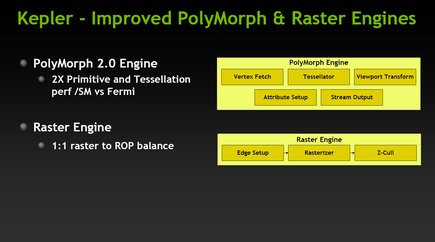
Du côté de l'interface mémoire enfin, Kepler introduit quelques changements. Il n'est ainsi plus question de bus mémoire 384 bits ! La puce devra faire avec quatre contrôleurs GDDR5 de 64 bits chacun. Au total, le GeForce GTX 680 bénéficie donc d'un bus mémoire interfacé en 256 bits et la principale nouveauté ici, c'est la prise en charge de fréquence de fonctionnement élevée pour la mémoire. NVIDIA est ainsi le premier à annoncer une fréquence de 6 008 MHz pour la mémoire (en réalité 1 502 MHz de fréquence de base) soit peu ou prou du 6 Gbps. La hausse de fréquence devrait compenser la perte de performances induite par la réduction du bus mémoire.
NVIDIA introduit son Turbo Boost : GPU Boost

Si certains se souviennent du Link Boost des anciens chipsets nForce... vous pouvez tout oublier ! En effet, il est ici question avec GPU Boost d'un mix de technologie logicielle et matérielle censée auto-optimiser la carte, en clair augmenter dynamiquement la fréquence de la puce, pour que celle-ci délivre les meilleures performances en fonction des conditions d'utilisation.
Pour ce faire, on retrouve sur la carte des composants dédiés à la surveillance de la consommation électrique de la puce graphique, et ce afin de s'assurer que celle-ci reste dans les normes prédéfinies. De la même manière, les circuits mis en place par NVIDIA permettent de mesurer la consommation de la partie mémoire, mais aussi le rendement de l'étage d'alimentation.
Sur le papier, NVIDIA nous propose une sorte de Turbo Boost à la Intel : totalement autonome et sans profil dans les pilotes ou intervention manuelle de l'utilisateur, la puce voit sa fréquence de fonctionnement augmenter si les conditions le permettent. Il s'agit de tirer profit des moments pendant lesquels le TDP maximal défini pour la carte (195 Watts pour la GeForce GTX 680) n'est pas atteint en utilisant la marge restante pour augmenter les fréquences.

Alors que NVIDIA communique sur une fréquence de fonctionnement officielle de base de 1 006 MHz pour la puce graphique, la technologie GPU Boost est censée permettre d'atteindre les 1 058 MHz de fréquence boostée. Alors 50 MHz ça n'a l'air de rien, mais c'est tout de même pas loin de 5% sur le papier. Mais GPU Boost ne devrait pas s'arrêter là : NVIDIA précise que dans bien des cas, le boost obtenu devrait permettre de taquiner les 1,1 GHz, pour peu que la consommation électrique du GPU demeure dans les normes.
Il est intéressant de soulever une différence notable avec ce qui se pratique chez AMD où la consommation est estimée selon l'activité des différentes unités de la puce et non mesurée via des circuits additionnels. Dès lors, on se dit que d'un échantillon de carte NVIDIA à l'autre, les résultats du GPU Boost pourraient être assez contrastés du fait d'une grande variabilité entre les cartes... ce qui expliquerait cette communication sur une fréquence Turbo supérieure d'à peine 50 MHz à la fréquence nominale.
Tout pour la qualité d'image
NVIDIA profite de Kepler pour introduire diverses nouveautés fonctionnelles visant à améliorer la qualité d'image. Toutes ces nouveautés ne sont du reste pas exclusives à Kepler et devraient voir le jour, si tout va bien, sur Fermi.La première d'entre elles concerne la VSync ou synchronisation verticale. On pensait ce concept démodé et pourtant... NVIDIA le remet au cœur de l'actualité. On sait qu'en jeu, si la synchronisation verticale n'est pas active, on observe des déchirements de l'image lors des scènes d'action (l'image est comme coupée en deux avec une ligne à un endroit). Le problème c'est que lorsque la synchronisation verticale est active, si jamais le nombre moyen d'images à la seconde passe sous les 60 lors d'une scène particulièrement chargée, l'écran va basculer à une fréquence de rafraichissement bien inférieure à la valeur moyenne de 60 Hz (typiquement 30 Hz) provoquant cette fois-ci des saccades.
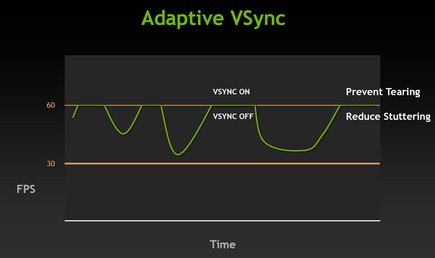
V-Sync adaptative
Pour tenter de remédier à la problématique, NVIDIA propose la synchronisation verticale adaptative à partir de la version 300 de ses pilotes. Le pilote graphique va automatiquement activer ou désactiver la synchronisation verticale pour afficher les images à une cadence plus régulière, afin de minimiser les effets de saccade. Cette nouveauté concerne tout autant le GeForce GTX 680 que les anciennes GeForce.
Activation dans les pilotes de la synchronisation vertical adaptative
L'autre nouveauté introduite par NVIDIA pour améliorer la qualité d'image est cette fois-ci plus directement liée au traitement des scènes qu'à leur simple affichage. La firme de Santa-Clara profite de la sortie de Kepler pour généraliser la technologie FXAA, une méthode de post-processing visant à réduire les effets d'escalier. Le FXAA est censé prodiguer un résultat similaire à un anti-aliasing à plusieurs échantillons classique tout en étant plus véloce et moins gourmand en mémoire vidéo. Déjà implémentée au cœur de certains jeux comme Age of Conan ou Batman Arkham City, la fonctionnalité FXAA a évolué au fil du temps et la nouveauté c'est qu'elle est maintenant accessible depuis les pilotes NVIDIA ce qui permet d'en profiter avec n'importe quel titre vidéo-ludique.

Filtrage FXAA à l'oeuvre
Quatre écrans sur une seule carte !
Parmi les nouveautés de l'architecture Kepler figure un tout nouveau moteur d'affichage. Celui-ci revient sur une lacune bien connue des GeForce : leur incapacité à piloter un large nombre d'écrans. On se souvient qu'AMD avait marqué les esprits au lancement des Radeon HD 5800 avec la fonctionnalité EyeFinity permettant de piloter un maximum de six écrans par carte. Avec Kepler, NVIDIA ne va pas aussi loin mais propose de piloter depuis une seule carte un maximum de 4 écrans.Pour les joueurs, cela se traduit par trois écrans destinés au jeu, c'est ce que NVIDIA appelle le Surround, le quatrième écran étant dédié à l'affichage de son bureau Windows pour garder par exemple le contact avec ses amis sur Windows Live Messenger. On retiendra surtout que NVIDIA n'impose pas l'utilisation de hub DisplayPort pour faire fonctionner sa solution Surround, même si contrairement à AMD, NVIDIA ne peut aller au-delà des quatre écrans.

Au passage, NVIDIA propose de nouvelles fonctionnalités logicielles comme la possibilité de positionner la barre des tâches Windows sur l'écran central ou encore d'agrandir une fenêtre sur un seul écran... Merci !
Le moteur d'affichage de la GeForce GTX 680 est compatible HDMI 1.4a, prend en charge les écrans 4K avec une résolution de 3840 x 2160 pixels et gère les multiples flux audio. Au passage, la puce gère le DisplayPort 1.2.
Un nouvel encodeur vidéo... matériel : NVENC
Kepler est aussi l'occasion pour NVIDIA de faire évoluer sa solution d'encodage vidéo. Si jusqu'à présent NVIDIA se basait sur la puissance de calcul de ses puces pour accélérer les opérations d'encodage, Kepler profite dorénavant d'un moteur matériel d'encodage dédié et baptisé NVENC. Le nom n'est peut-être pas super sexy mais au diable les détails.Plutôt que d'utiliser les cœurs CUDA pour accélérer l'encodage vidéo, le recours à un bloc fixe devrait permettre de ménager la consommation électrique tout en maximisant l'efficacité. Il faudra bien sûr que les logiciels existants soient mis à jour pour profiter des nouvelles possibilités offertes par NVENC. Sur le papier, le bloc supporte les profils H.264 Base, Main et High Profile 4.1 en plus du MVC. La résolution maximale supportée est le 4096x4096 et NVIDIA communique sur une vitesse d'encodage Full HD (1080p donc) 8 fois supérieure au temps réel. En clair, encoder 16 minutes de vidéo HD 1080p à 30 images/seconde devrait se faire en deux minutes.
Encodage vidéo depuis MediaEspresso tirant parti de NVENC
Nous avons pu essayer une version Beta de MediaEspresso, le logiciel de conversion vidéo de Cyberlink avec la GeForce GTX 680. Nous avons converti un fichier MKV 720p d'une durée de 43 minutes vers le format iPhone 4S. Nous effectuons l'opération avec la GeForce GTX 680 et l'accélération NVENC puis avec une GeForce GTX 580 et son accélération CUDA et également en mode CPU seul.
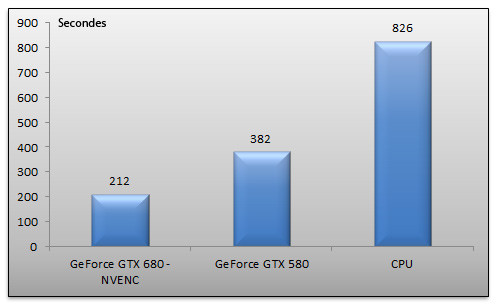
Le résultat parle de lui même : alors qu'il faut pas loin de 13 minutes à notre processeur pour venir à bout de l'opération, la GeForce GTX 680 fait le job en à peine plus de trois minutes. De son côté la GeForce GTX 580 mettra un peu plus du double de temps, soit six minutes, pour achever l'encodage. Et ce n'est pas tout ! Il est intéressant de s'attarder sur la consommation électrique de notre système, relevée à la prise, lors des encodages :
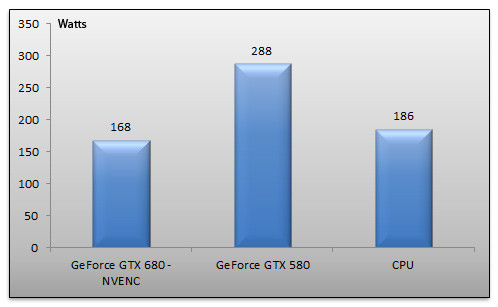
En mode CPU seul la consommation de la machine est d'une vingtaine de Watts supérieure à la consommation avec le GeForce GTX 680 pour un temps d'encodage qui sera rappelons-le quatre fois supérieur. Quant à la consommation du système en GeForce GTX 580, elle explose tout simplement : une centaine de watts de plus qu'en mode CPU seul !
GeForce GTX 680 : la puce
Répondant au nom de code GK104, la puce GeForce GTX 680 compte 3,54 milliards de transistors et est fabriquée selon le processus en 28 nm de TSMC. Il est intéressant de comparer le nombre de transistors de la petite dernière de NVIDIA avec celui communiqué par AMD pour son Radeon HD 7970. La version la plus évoluée de Tahiti revendique pas loin de 4,3 milliards de transistors, soit significativement plus que Kepler.
Le die de Kepler
Pour ce qui est des fréquences de fonctionnement, la puce GeForce GTX 680 opère à une fréquence de base de 1 006 MHz comme décrit précédemment, y compris lorsque nous considérons ses unités CUDA. La technologie GPU Boost dont nous vous parlions précédemment permettra de grappiller quelques MHz supplémentaires en fonction des conditions. Du côté de la mémoire, Kepler est accompagné de 2 Go de mémoire GDDR5 opérant à 1 502 MHz pour une bande passante théorique maximale de 192,26 Go/s.
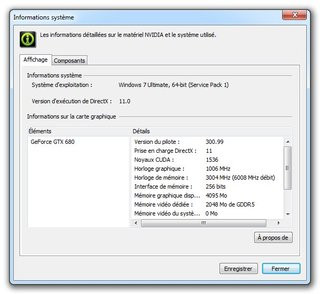
Le GeForce GTX 680 vu par les pilotes NVIDIA
Côté consommation, la puce ne profite hélas pas d'équivalent au ZeroCore Power d'AMD. De fait, elle ne peut pas rivaliser avec le mode très faible consommation des Radeon HD 7000. Rappelons qu'avec Tahiti, AMD peut faire tomber la consommation de la puce graphique à 3 Watts... Ce n'est pas le cas ici et il faudra faire avec un ventilateur qui tourne en permanence.
| Radeon HD 7970 | GeForce GTX 580 | GeForce GTX 680 | |
| Interface | PCI-Ex. 16x - Gen3 | PCI-Ex. 16x - Gen2 | PCI-Ex. 16x - Gen3 |
| Gravure | 0,028 µ | 0,040 µ | 0,028 µ |
| Transistors | 4,3 Milliards | 3 Milliards | 3,54 Milliards |
| T&L | DirectX 11.1 | DirectX 11 | DirectX 11.1 |
| Stream Processors | 2048 | 512 | 1536 |
| Unités ROP | 32 | 48 | 32 |
| Unités de texture | 128 | 64 | 128 |
| Mémoire embarquée | 3072 Mo | 1536 Mo | 2048 Mo |
| Interface mémoire | 384 bits | 384 bits | 256 bits |
| Bande passante | 264 Go/s | 192,4 Go/s | 192,26 Go/s |
| Fréquence GPU | 925 MHz | 772 MHz | 1006 MHz (base) |
| Fréquence Stream Processors | 925 MHz | 1544 MHz | 1006 MHz (base) |
| Fréquence mémoire | 1375 MHz - GDDR5 | 1002 MHz - GDDR5 | 1502 MHz - GDDR5 |
GeForce GTX 680 : la carte

La bonne nouvelle, c'est que le dispositif de refroidissement est plutôt silencieux, d'autant que NVIDIA a travaillé l'acoustique pour faire en sorte que même lorsque la carte s'échauffe, la nuisance sonore soit la plus sourde possible (à l'inverse du mode sèche-cheveux de certaines des dernières Radeon que nous avons pu tester). En revanche, point n'est question ici de technologie similaire à ce que propose AMD avec ses Radeon HD 7000, notamment au niveau de l'arrêt du ventilateur lorsque la carte entre en mode idle.
Au niveau de son alimentation électrique, la carte est dotée d'un circuit à 4 phases pour la puce graphique et deux phases pour la mémoire. Du reste, en s'attardant sur le dos du PCB de la carte, on observe que le contrôleur d'alimentation est soudé sur un PCB additionnel. Interrogé à ce sujet, NVIDIA nous indique que ce choix de design lui permet de changer de contrôleur d'alimentation sans refaire le PCB de toute la carte graphique.

Gros plan sur le contrôleur d'alimentation sur-soudé
En matière de branchement, la carte exige le raccordement de deux connecteurs PCI-Express 6 broches avec un positionnement original : les connecteurs sont placés l'un sur l'autre. Une astuce censée permettre d'optimiser le design de la carte et in-fine sa taille.









Du côté des fréquences de fonctionnement, la carte opère aux fréquences édictées par NVIDIA : 1 006 MHz pour la puce graphique et 1 502 MHz pour les 2 Go de mémoire GDDR5. Puisque la carte profite du GPU Boost nous avons pris soin de vérifier ses fréquences en charge. La plupart du temps, la puce grimpe à un maximum de 1 100 MHz pour se stabiliser bien souvent autour des 1 097 MHz.

Observation des fréquences de fonctionnement avec l'utilitaire EVGA
Niveau connectique, la carte propose deux ports DVI, un connecteur HDMI et une prise DisplayPort. On retrouve deux connecteurs SLI sur la tranche. Quant au TDP de la carte, il est fixé par NVIDIA à 195 Watts.
Overclocking
Puisque la puce est maintenant surveillée à tous les niveaux de sa consommation et alors que NVIDIA propose sa technologie de GPU Boost, l'overclocking de Kepler s'en trouve modifié de manière conséquente. Tout d'abord, l'ensemble des outils habituellement utilisés par les overclockers ne fonctionne plus. Ainsi en attendant une prochaine mise à jour, la version actuelle de GPU-Z vous affichera un écran rouge alors que les autres utilitaires ne permettent pas de modifier la fréquence de fonctionnement de la puce. Pour ce test, nous avons utilisé la version 3.00 (bêta) de l'outil EVGA en cours de développement chez le fabricant de cartes graphiques et déjà compatible avec Kepler. Signalons au passage que NVIDIA ne fournit pour l'heure aucun outil de son cru pour l'overclocking, pas même le célèbre System Tools.L'outil ne permet pas de modifier la tension d'alimentation de la puce. Toutefois il permet d'ajuster le seuil de tolérance pour l'enveloppe de consommation de la carte et de modifier ses fréquences de fonctionnement. Attention toutefois on modifie ici l'offset, c'est-à-dire le différentiel entre la fréquence de base et la fréquence turbo. En réglant cette valeur à 100 MHz, je rajoute 100 MHz à la fréquence maximale de GPU Boost, une fréquence qui est susceptible de chuter si la consommation du GPU devient trop importante notamment.

Overclocking du GeForce GTX 680 : ici à 1260 MHz
Durant nos tests, nous avons visé les 1300 MHz de fréquence sans succès puisqu'au bout de deux minutes notre benchmark a tout simplement planté. Nous avons visé par la suite les 1 260 MHz, une fréquence qui semble stable, mais a été retoquée après quelques minutes par la puce qui a dégradé automatiquement celle-ci à 1 247 MHz puis 1 227 MHz et enfin 1 202 MHz. Pas de souci en revanche du côté de la mémoire où nous avons pu grimper assez haut. En terme de performances, sous 3DMark 11, l'overclocking donne le résultat suivant :
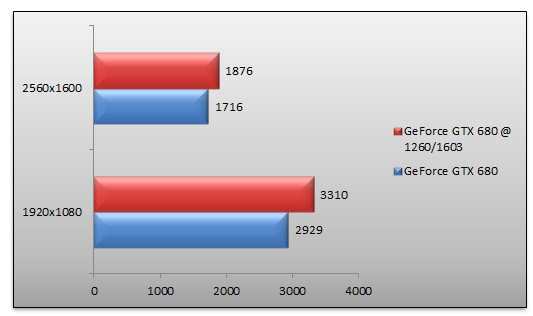
Alors que l'overclocking nous permet de gagner 13% de performance face aux fréquences de référence en 1920x1080, le gain en 2560x1600 est plus modéré et ne dépasse pas les 9%.Au cœur de ce dossier, nous retrouvons les tests de performance. Voici la configuration utilisée :

- Carte mère Asus Maximus Rampage IV Extreme (BIOS 1101),
- Processeur Intel Core i7 3960X,
- 16 Go Mémoire DDR3-1600 Corsair @ 1600,
- SSD Samsung Serie 830 256 Go
Côté pilotes, nous avons utilisé les Catalyst 8.951.1 mis à disposition par AMD tandis que nous avons recours aux pilotes NVIDIA 300.99. Naturellement la machine opérait sous Windows 7 Edition Intégrale avec Service Pack 1 x64. Nous retenons deux résolutions pour ce test : le 1920x1080 des écrans 23,6/24 pouces notamment et le 2560x1600.
3DMark 11 - Mode Extrême
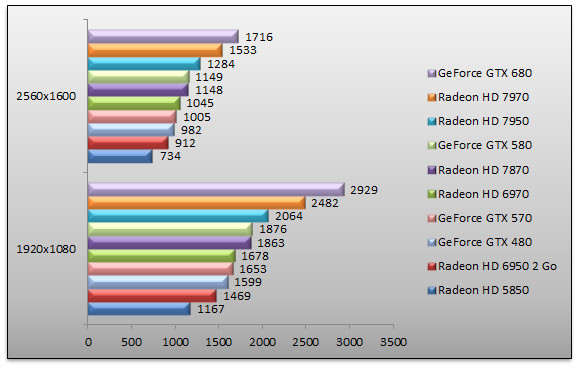
On démarre avec une vieille connaissance, 3DMark 11. Le GeForce GTX 680 affiche d'emblée sa suprématie et se hisse en pôle position avec des performances 12% supérieures au Radeon HD 7970 en 2560x1600. Face au GeForce GTX 580 le gain atteint 49% dans cette même résolution.
Dirt 3 - Ultra - 4x
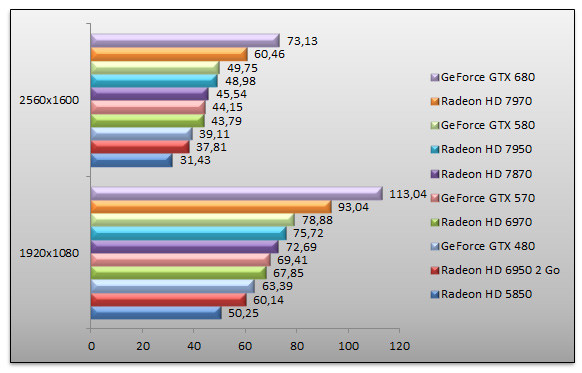
Enchaînons avec Dirt 3, jeu de course DirectX 11. Là encore le GeForce GTX 680 est largement en tête. En 1920x1080 son avantage est de 21% face au Radeon HD 7970 qui est pour la petite histoire la deuxième carte la plus rapide de notre sélection. Face au GeForce GTX 580, la petite dernière de NVIDIA se montre 43% plus rapide. Quant à l'écart avec le GeForce GTX 480, il va pratiquement du simple au double.
Mafia II - AA - AF 16x
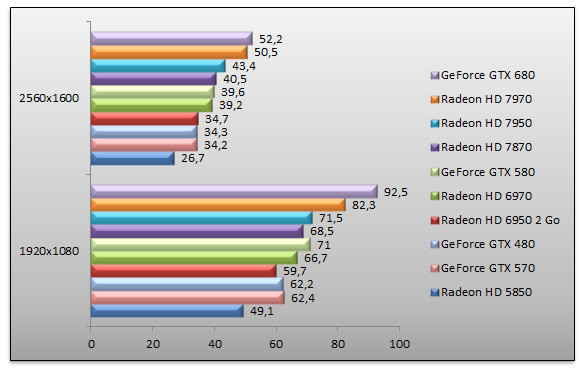
Mafia II a l'avantage de remettre quelque peu les pendules à l'heure en ramenant l'avantage de Kepler a des niveaux plus raisonnables. Certes en 1920x1080, le GeForce GTX 680 est 12% plus rapide que le Radeon HD 7970 et au passage 30% plus performant que le GeForce GTX 580. Mais en 2560x1600 cette avance s'étiole pour n'être plus que de 3% par rapport au Radeon HD 7970.
Unigine 2.5 - Heaven - High - AF 16x
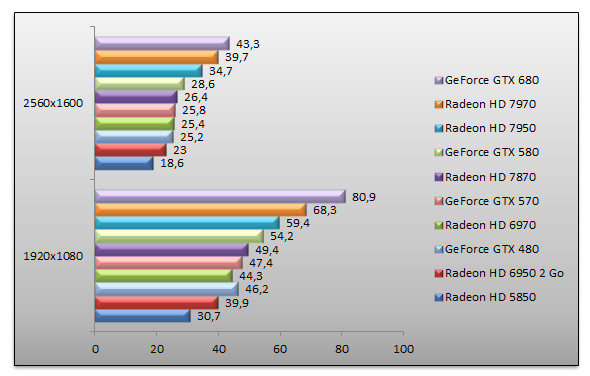
Parfaitement synthétique, Unigine n'en demeure pas moins largement favorable au GeForce GTX 680. En 1920x1080 la carte de NVIDIA est 18% plus rapide que le Radeon HD 7970, sa concurrente directe. On note une fois de plus que l'avantage du GeForce GTX 680 sur le Radeon HD 7970 dégringole au fur et à mesure que la résolution augmente. En 2560x1600, les performances de la carte de NVIDIA ne sont plus que 9% supérieures au Radeon HD 7970. Face au GeForce GTX 580, le GeForce GTX 680 se montre 51% plus rapide.
Batman Arkham City - FXAA - MVSS - HBAO
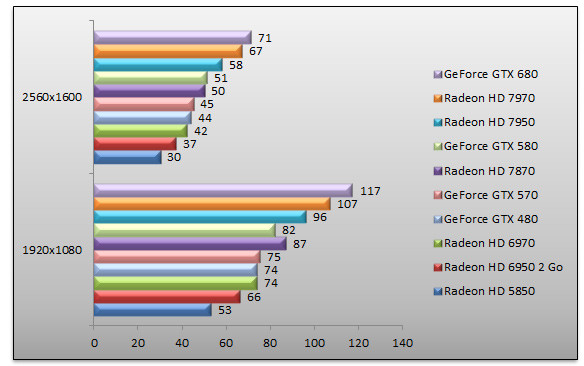
Dans son dernier opus, Batman a impressionné... les joueurs. Peut être moins les joueurs PC qui ont du faire avec un nombre incroyable de bugs à présent corrigés... pour la plupart. Quoi qu'il en soit, le GeForce GTX 680 est ici encore premier. La petite dernière de NVIDIA dispose d'une avance de 9% en 1920x1080 sur le Radeon HD 7970 et de seulement 6% en 2560x1600 toujours face au Radeon HD 7970. Face au GeForce GTX 580, le GeForce GTX 680 se montre 39% plus rapide.
Crysis 2 - DirectX 11 - Ultra - Textures HR
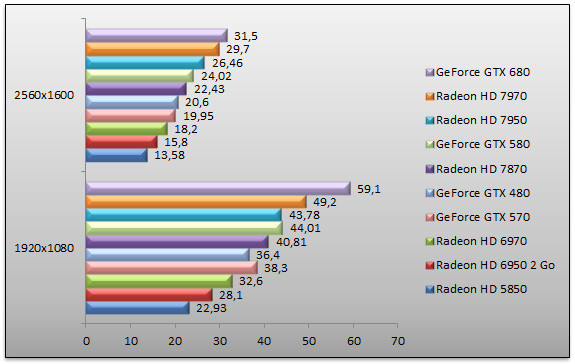
Retour sous Crysis 2 testé avec Fraps. Nous retrouvons le GeForce GTX 680 en tête avec un avantage de 20% sur le Radeon HD 7970 en 1920x1080 et seulement 6% en 2560x1600. Face au GeForce GTX 580 qu'elle remplace, la GeForce GTX 680 est 34% plus rapide.
Battlefield 3 - Ultra - AA 4x / AF 16x - Semper-Fi
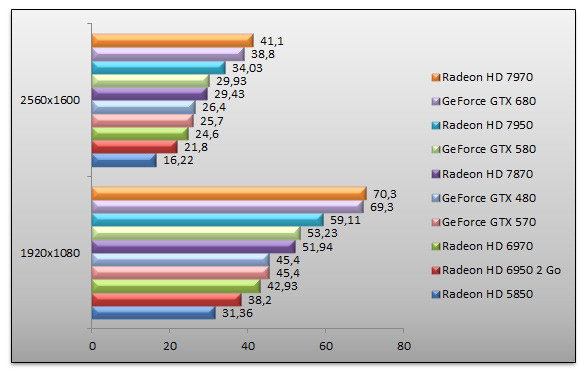
Surprise ! Battlefield 3 ne consacre pas le GeForce GTX 680. La carte de NVIDIA est ici très légèrement en retrait face au Radeon HD 7970. Une situation un rien ennuyeuse pour NVIDIA. Rappelons que nous testons le jeu par le biais de FRAPS et que la map utilisée est ici la mission Semper-Fi. Si Kepler échoue à ravir la première place, la carte demeure 30% plus rapide que le GeForce GTX 580.
Battlefield 3 - Ultra - AA 4x / AF 16x - Kaffarov
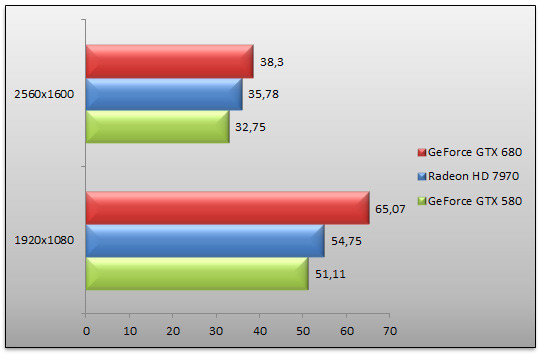
Nous avons eu à coeur de vérifier le comportement du GeForce GTX 680 avec une autre scène de Battlefield 3, toujours en utilisant FRAPS. Cette fois-ci nous utilisons une scène extérieure, map Kaffarov. Le résultat est plus en faveur de NVIDIA, le GeForce GTX 680 repassant devant le Radeon HD 7970 : en 1920x1080 la carte de NVIDIA est 19% plus rapide que le modèle AMD mais cet avantage tombe à 7% en 2560x1600. L'écart de performances avec le GeForce GTX 580 s'établit à 27%, en 1920x1080.
STALKER - Call Of Pripyat - Extrême
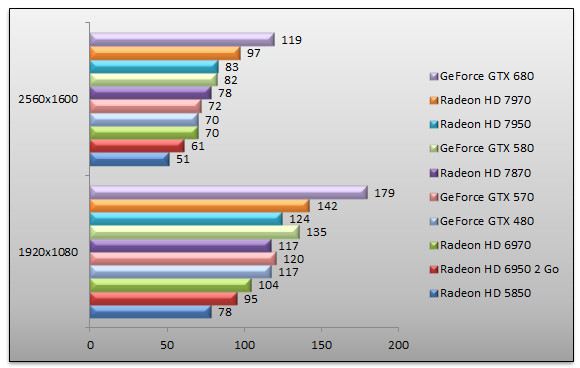
Pour ce titre DirectX 11, le GeForce GTX 680 s'affiche comme la carte la plus rapide et de loin. En 2560x1600 NVIDIA l'emporte sur le Radeon HD 7970 grâce à un score 22% supérieur. La remplaçante du GeForce GTX 580 se montre 45% plus rapide.
Metro 2033 - Très haut - AAA - AF 16x
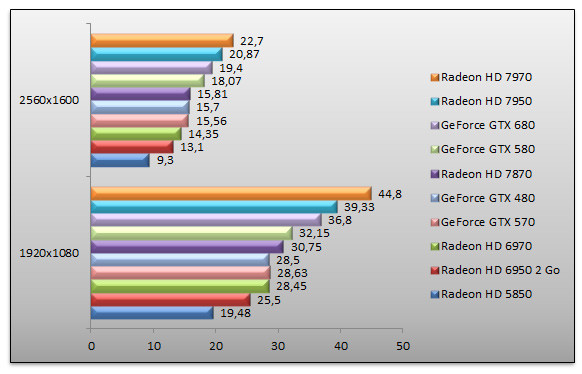
Testé avec FRAPS, Metro est l'autre surprise de ce test. Le GeForce GTX 680 n'est pas bon, clairement, handicapé par un nombre d'unités ROP trop faible et une quantité de mémoire vidéo restreinte. Du coup, le Radeon HD 7970 est en tête avec des performances 17% supérieures en 2560x1600. Quant à l'écart de performances avec le GeForce GTX 580, il est de 7%, pas de quoi fouetter un chat. Cela confirme s'il en était besoin qu'en cas d'anti-aliasing conséquent Kepler a quelques difficultés.
Tom Clancy's H.A.W.X. 2 - DirectX 11
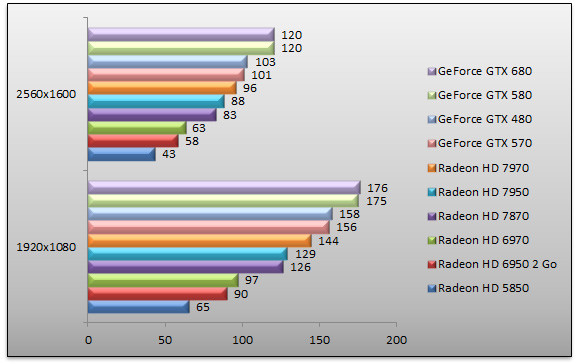
Largement optimisé pour les GPU NVIDIA à son lancement, H.A.W.X. 2 fait la part belle à la géométrie et à la tesselation. Si nous retrouvons le GeForce GTX 680 en tête, on est surpris de constater qu'il est à égalité avec le GeForce GTX 580. La raison est à chercher du côté des ROP : le GeForce GTX 580 a une puissance en la matière supérieure au GeForce GTX 680 ce qui se ressent ici. Cela n'empêche pas le GeForce GTX 680 d'être 25% plus rapide que le Radeon HD 7970 en 2560x1600. Et si GeForce GTX 680 et GeForce GTX 580 font jeu égal, le GeForce GTX 680 est 16% plus rapide que le GeForce GTX 480.
Consommation
Comme à chaque fois, nous avons vérifié la consommation électrique de nos cartes graphiques. Nous procédons à deux mesures : au repos, sur le bureau Windows, puis en charge avec un 3DMark 11 Extreme s'exécutant en 2560x1600. La mesure est effectuée à la prise, au moyen d'un wattmètre. Il s'agit donc de la consommation électrique globale de notre machine de test.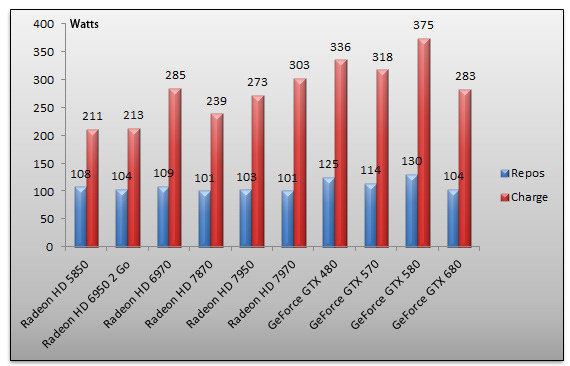
Au repos, la GeForce GTX 680 semble être moins vorace. Certes la consommation de notre système ne tombe pas aussi bas qu'avec une Radeon HD 7000 mais on gagne une trentaine de watts face au GeForce GTX 580. En charge, la carte se montre peut-être encore plus surprenante ! Avec 283 Watts relevés, la GeForce GTX 680 consomme une vingtaine de Watts de moins que la Radeon HD 7970 alors que la comparaison avec Fermi fait mal ! Dans les mêmes conditions, le GeForce GTX 580 consomme près d'une centaine de watts de plus !
Conclusion

À défaut d'ouvrir le bal des cartes graphiques de nouvelle génération, AMD ayant été le premier à abattre ses cartes et surtout des technologies comme DirectX 11.1, le PCI-Express 3.0 ou encore la gravure en 28 nm, NVIDIA réplique enfin à son concurrent de toujours.
Très attendue, la nouvelle GeForce GTX 680 profite d'une toute nouvelle architecture répondant au nom de code Kepler. Une architecture qui bien que nouvelle n'est au final qu'une évolution logique de Fermi, le nom de l'architecture au cœur des GeForce GTX 480 et 580 notamment. Evolution certes, mais dans le très bon sens du terme. Les ingénieurs de NVIDIA ont en effet retravaillé l'architecture pour la rendre plus efficace, plus puissante et surtout moins gourmande en énergie. Le résultat est probant puisque non content d'être largement plus véloce que l'ancienne génération de GeForce, Kepler consomme bien moins.
Pour autant, tout n'est pas parfait. Certains choix de dimensionnement de l'architecture notamment au niveau du nombre d'unités ROP nous laissent songeurs, alors que la taille physique de la puce (et celle de la carte !) semble bien trop raisonnable pour un circuit NVIDIA. Les mauvaises langues auraient tendance à dire que cette GeForce GTX 680 était destinée à être une GeForce GTX 660, c'est-à-dire une puce milieu de gamme. Mais quand bien même, on reste agréablement surpris par les très bonnes prestations globales de l'architecture, sa consommation modérée ou encore ses performances. Le ratio performance par watt est indubitablement en progrès à ce détail près que comparativement une Radeon HD 7850 offrira un meilleur compromis... mais il est vrai qu'il ne s'agit pas de la même classe de GPU.

En matière de performances justement, le GeForce GTX 680 est sans conteste plus rapide que son prédécesseur, mais face au Radeon HD 7970, le bilan est plus mitigé. Dans la plupart des jeux, la petite dernière de NVIDIA est entre 5 et 20% plus rapide que sa concurrente directe, la Radeon HD 7970. Oui mais voilà sous Battlefield 3, jeu emblématique de dernière génération, la carte d'AMD est 5% plus rapide ! Alors certes, notre scène de référence n'était vraisemblablement pas en faveur de NVIDIA comme l'a montré notre second test. Qui plus est Metro 2033 met en exergue les limites de Kepler alors que H.A.W.X. 2 pourtant supposé tirer largement parti de la puissance géométrique toujours croissante de nos puces positionne GeForce GTX 580 et GeForce GTX 680 à parfaite égalité. Diverses raisons peuvent expliquer ce manque d'homogénéité ou de constance face au Radeon HD 7970 : le GeForce GTX 680 se contente de 2 Go de mémoire vidéo contre 3 Go pour AMD alors que la puce peut être limitée par un nombre réduit d'unités ROP, c'est particulièrement vrai en cas d'anti-aliasing intensif, tandis que le compilateur des pilotes NVIDIA pourra encore être optimisé à l'avenir.
Au-delà des performances, l'arrivée de la technologie GPU Boost nous laisse également mitigés. Sur le papier, il s'agit d'une très bonne idée dont le seul but est de maximiser les performances offertes par la carte. Dans les faits, la technologie peut être soumise à de fortes variations en fonction de la carte, de la puce employée ou encore de l'efficacité du système de refroidissement alors que GPU Boost opacifie l'overclocking. L'utilisateur béotien trouvera probablement que l'overclocking est simplifié, le power user que nous sommes sera perdu et pestera contre la variabilité de cet overclocking où l'on ne sait jamais vraiment ce qui se passe.

On retiendra également de Kepler l'arrivée d'un moteur d'affichage au niveau, ou presque, de la concurrence avec la possibilité de piloter jusqu'à quatre écrans depuis une seule carte. En prime, le nouvel encodeur vidéo matériel baptisé NVEnc semble donner des résultats véritablement prometteurs avec les logiciels optimisés. Quant à la carte de référence proposée par NVIDIA elle est tout à fait plaisante tant au niveau de sa taille modérée que de son design et sa discrétion. Difficile toutefois de ne pas regretter un équivalent à la technologie Zero Core Power d'AMD, en ces temps de green computing NVIDIA aurait pu pousser sa démarche de meilleur ratio performance/watt au bout.
Annoncée au prix public conseillé de 499 euros TTC, la GeForce GTX 680 s'affiche bon an mal an comme une excellente alternative au Radeon HD 7970 pour peu que les stocks soient au rendez-vous et que les revendeurs ne décident pas de marger à plein tube. Vivement les déclinaisons !








