
Surveiller le trafic réseau, identifier les vulnérabilités et optimiser les performances représentent des défis majeurs pour les entreprises. Cette démarche exige une méthodologie précise et des outils adaptés pour analyser un réseau de manière efficace.

L'analyse réseau constitue un pilier fondamental de la cybersécurité moderne. Elle permet d'identifier les anomalies, d'anticiper les pannes et de détecter les intrusions avant qu'elles ne compromettent l'infrastructure. Cette surveillance continue offre une visibilité complète sur l'utilisation de la bande passante, les connexions suspectes et les performances des équipements. Les administrateurs peuvent ainsi prendre des décisions éclairées pour maintenir un environnement réseau stable et sécurisé, tout en anticipant les besoins futurs en termes de capacité et d'évolution technologique.
La complexité croissante des infrastructures informatiques modernes, avec leurs environnements hybrides mêlant on-premise et cloud, multiplie les points d'entrée potentiels pour les cyberattaques. Les réseaux d'entreprise intègrent désormais une multitude d'équipements connectés, des serveurs traditionnels aux objets IoT, créant un écosystème difficile à superviser sans outils appropriés. Cette hétérogénéité technologique nécessite une approche structurée et des compétences spécialisées pour maintenir un niveau de protection optimal.
Maîtriser les fondamentaux de l'analyse trafic réseau
Comprendre l'architecture réseau existante
L'inventaire des périphériques connectés représente la première étape cruciale de toute démarche d'analyse réseau. Cette cartographie exhaustive inclut les routeurs, commutateurs, serveurs, postes de travail et équipements IoT présents sur l'infrastructure. Chaque élément doit être répertorié avec ses caractéristiques techniques, son rôle dans l'architecture globale et ses vulnérabilités potentielles. Cette approche méthodique permet d'identifier les équipements obsolètes, les configurations défaillantes et les points de défaillance unique qui pourraient compromettre la continuité de service.

La documentation de la topologie réseau facilite l'identification des points critiques et des zones potentiellement vulnérables. Cette vue d'ensemble permet d'établir une baseline des performances normales et de comprendre les flux de données entre les différents segments. Les administrateurs doivent cartographier les VLAN, les sous-réseaux et les politiques de routage pour anticiper l'impact des modifications futures. Cette documentation vivante s'enrichit au fil des évolutions et sert de référence lors des incidents.
Les protocoles utilisés (TCP, UDP, ICMP) et leur répartition donnent des indications précieuses sur la nature du trafic circulant dans l'infrastructure. Une analyse approfondie révèle les applications les plus consommatrices de bande passante et permet d'identifier les communications non conformes aux politiques de sécurité. Cette visibilité protocollaire aide à détecter les tentatives d'exfiltration de données, les connexions vers des serveurs de commande et contrôle, ou l'utilisation de tunnels non autorisés.
Identifier les métriques essentielles
La latence mesure le temps nécessaire pour qu'un paquet traverse le réseau depuis sa source jusqu'à sa destination. Des valeurs élevées indiquent souvent des congestions, des problèmes de routage ou des équipements surchargés. Cette métrique impacte directement l'expérience utilisateur et la performance des applications interactives. Les administrateurs doivent établir des seuils d'alerte basés sur les exigences métier et surveiller l'évolution de cette métrique dans le temps pour détecter les dégradations progressives.

Le débit (throughput) quantifie la quantité de données transmises par unité de temps et révèle la capacité réelle du réseau comparée à sa capacité théorique. Cette mesure objective permet d'évaluer l'efficacité de l'infrastructure et d'identifier les goulots d'étranglement. Les variations importantes du débit peuvent signaler des problèmes matériels, des attaques par déni de service ou des applications défaillantes consommant excessivement les ressources réseau. La corrélation entre débit et latence fournit des informations précieuses sur l'état de santé global de l'infrastructure.
Le taux de perte de paquets signale des dysfonctionnements matériels, une saturation du réseau ou des attaques actives. Un pourcentage supérieur à 1% nécessite une investigation immédiate car il impacte la fiabilité des communications et peut masquer des activités malveillantes. La gigue (jitter) mesure la variation de la latence et impacte particulièrement les applications temps réel comme la VoIP ou la visioconférence. Ces métriques combinées offrent une vue complète de la qualité de service et permettent d'ajuster les paramètres réseau en conséquence.
Établir une surveillance continue
La collecte de données historiques permet d'identifier les tendances et les patterns d'utilisation réguliers ou saisonniers. Ces informations facilitent la planification de la capacité et l'anticipation des besoins futurs en bande passante ou en équipements. L'analyse des données historiques révèle également les anomalies récurrentes qui pourraient indiquer des problèmes systémiques nécessitant une intervention structurelle. Cette approche préventive réduit les coûts de maintenance et améliore la disponibilité des services.
Les alertes automatisées notifient les administrateurs lors de dépassements de seuils prédéfinis, permettant une intervention rapide avant que les problèmes n'impactent les utilisateurs finaux. Cette approche proactive réduit les temps d'intervention et limite l'impact des incidents sur l'activité métier. Les seuils doivent être ajustés régulièrement pour éviter les fausses alertes tout en maintenant une sensibilité suffisante pour détecter les anomalies réelles. L'escalade automatique garantit qu'aucun incident critique ne passe inaperçu.
L'analyse comportementale détecte les anomalies par rapport aux modèles d'usage habituels établis par apprentissage automatique. Cette technique révèle les activités suspectes qui échappent aux règles de sécurité traditionnelles basées sur des signatures connues. Les algorithmes d'intelligence artificielle identifient les déviations subtiles dans les patterns de communication, les volumes de données échangées ou les horaires d'activité, permettant de détecter les menaces persistantes avancées et les attaques zero-day.
Déployer les outils analyse réseau appropriés
Solutions de surveillance open source
Les plateformes de monitoring open source comme Nagios, Zabbix, PRTG et Cacti constituent la colonne vertébrale de du monitoring réseau pour de nombreuses organisations cherchant à maîtriser leurs coûts tout en maintenant une visibilité complète sur leur infrastructure. Ces solutions offrent des fonctionnalités robustes de collecte de métriques, de génération d'alertes et de reporting adaptées aux environnements hétérogènes mêlant équipements de différents constructeurs. Leur architecture modulaire permet une personnalisation poussée selon les besoins spécifiques de chaque organisation, tandis que leurs communautés actives développent constamment de nouveaux plugins pour s'adapter aux technologies émergentes. Les interfaces web intuitives facilitent la création de tableaux de bord personnalisés et la génération de rapports automatisés pour différents niveaux hiérarchiques, du technicien au management. Ces outils excellent particulièrement dans la surveillance de la disponibilité des services, le suivi des performances historiques et l'intégration avec les systèmes de ticketing existants pour automatiser la gestion des incidents.
Analyseurs de trafic spécialisés
Les analyseurs de paquets comme Wireshark, ntopng et SolarWinds Network Traffic Analyzer se concentrent sur l'inspection détaillée du trafic réseau pour identifier les anomalies de communication et analyser les performances applicatives. Ces outils capturent et décodent les paquets en temps réel ou à partir de fichiers de capture, offrant une visibilité granulaire sur les protocoles utilisés, les volumes échangés et les patterns de communication. Leur utilisation s'avère cruciale lors d'investigations de sûreté pour identifier l'origine d'une intrusion, analyser les techniques d'attaque ou reconstituer le déroulement d'un incident. Les fonctionnalités avancées de filtrage permettent d'isoler des flux spécifiques dans des captures volumineuses, tandis que les capacités de géolocalisation révèlent l'origine géographique des connexions suspectes. Ces solutions excellent également dans l'optimisation des performances en identifiant les applications consommatrices de bande passante, les protocoles inefficaces ou les configurations sous-optimales impactant l'expérience utilisateur.
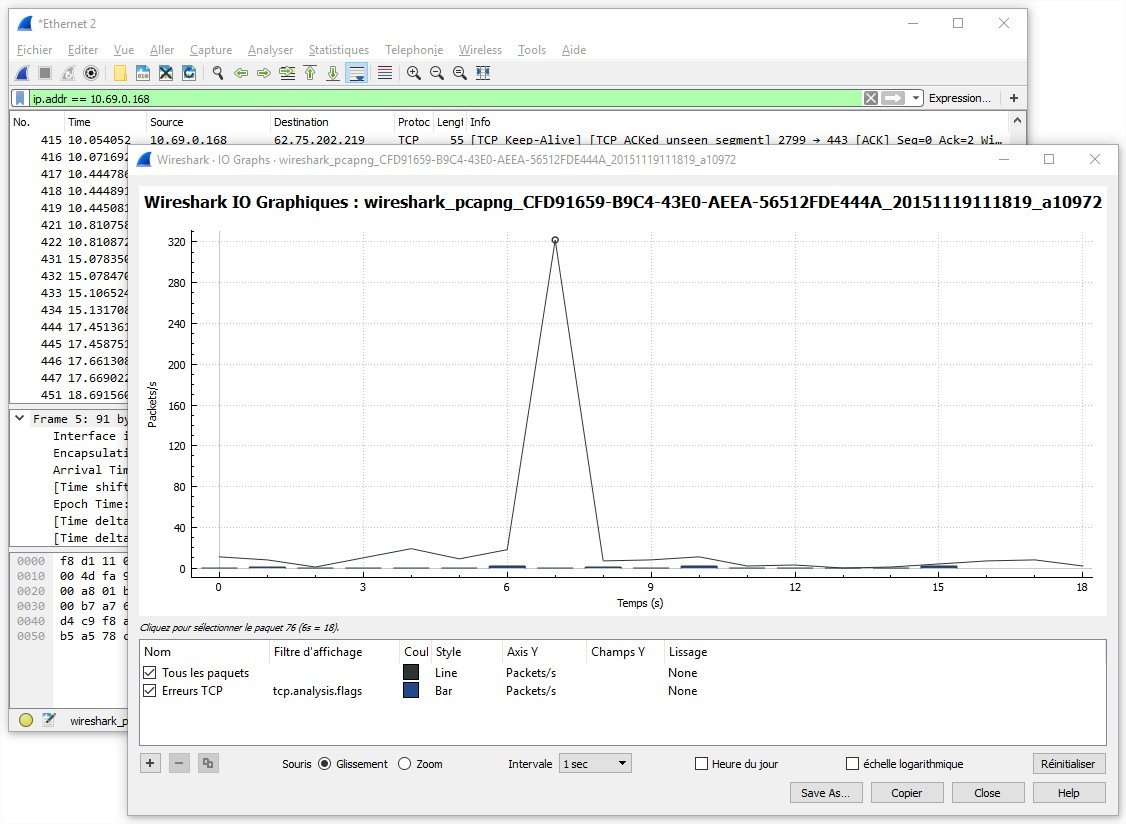
Outils de diagnostic réseau
Les utilitaires de diagnostic réseau tels que Nmap, Netstat, Traceroute et Iperf constituent des outils indispensables pour le troubleshooting et l'évaluation de la résilience des infrastructures informatiques. Ces solutions légères mais puissantes permettent d'identifier rapidement les problèmes de connectivité, de mesurer les performances réelles et de cartographier la surface d'attaque d'un réseau. Nmap excelle dans la découverte de services et la détection de vulnérabilités grâce à ses scripts automatisés, facilitant les audits réguliers et l'inventaire des équipements connectés. Les outils de mesure de performance comme Iperf fournissent des métriques objectives sur la bande passante disponible et la latence sous charge, essentielles pour valider les SLA et dimensionner correctement les liaisons réseau. Traceroute révèle les chemins de routage et les points de congestion, aidant à diagnostiquer les problèmes de connectivité complexes dans des infrastructures distribuées. Ces outils s'intègrent naturellement dans les scripts d'automatisation pour le monitoring continue et le diagnostic proactif des problèmes réseau.
Renforcer la sécurité et optimiser les performances réseau
Détecter les menaces et anomalies
L'analyse du trafic réseau révèle les connexions inhabituelles vers des destinations suspectes, souvent caractérisées par des patterns de communication non conformes aux usages métier. Ces communications peuvent indiquer la présence de malwares communiquant avec des serveurs de commande et contrôle, des tentatives d'exfiltration de données ou des activités de reconnaissance. La corrélation avec des bases de données de réputation IP et de domaines malveillants enrichit cette analyse et permet une qualification rapide des menaces.

La surveillance des volumes de données échangées détecte les exfiltrations potentielles et les transferts anormaux qui pourraient compromettre la confidentialité des informations sensibles. Des transferts massifs vers l'extérieur du réseau, particulièrement en dehors des heures ouvrables, nécessitent une investigation approfondie. L'analyse des patterns temporels révèle les activités automatisées suspectes et aide à distinguer les transferts légitimes des activités malveillantes.
L'identification des tentatives de connexion échouées révèle les attaques par force brute et les tentatives d'intrusion automatisées. Ces patterns récurrents signalent souvent des campagnes d'attaque coordonnées nécessitant des mesures de protection immédiates. La géolocalisation des sources d'attaque permet d'adapter les politiques de sécurité et de bloquer préventivement les plages d'adresses suspectes.
La détection d'anomalies protocolaires identifie les communications non conformes aux standards qui peuvent masquer des techniques d'évasion sophistiquées. Ces irrégularités incluent l'utilisation de ports non standard, l'encapsulation de protocoles ou les tentatives de contournement des politiques de sécurité. L'analyse comportementale des protocoles révèle les tentatives de tunneling non autorisé et les communications chiffrées suspectes.
Implémenter des mesures de protection
La segmentation réseau limite la propagation des menaces en isolant les zones critiques selon leurs niveaux de sensibilité et leurs besoins fonctionnels. Cette approche réduit la surface d'attaque et facilite le contrôle des accès en appliquant le principe du moindre privilège. Les micro-segments permettent un contrôle granulaire des communications entre applications et réduisent les risques de mouvement latéral des attaquants.

Les listes de contrôle d'accès (ACL) filtrent le trafic selon des règles prédéfinies basées sur les adresses sources et destinations, les ports et les protocoles. Ces politiques bloquent les communications non autorisées entre les segments réseau et appliquent les politiques de sécurité de l'entreprise. La révision régulière des ACL garantit leur pertinence face à l'évolution des besoins métier et des menaces.
La surveillance des certificats SSL/TLS détecte les connexions chiffrées suspectes et les tentatives d'usurpation d'identité par certificats frauduleux. L'inspection du trafic chiffré révèle les communications vers des domaines malveillants et les tentatives de contournement des politiques. La validation des chaînes de certification et la détection des certificats auto-signés renforcent la confiance dans les communications sécurisées.
Les systèmes de prévention d'intrusion (IPS) analysent le trafic en temps réel pour bloquer les attaques connues et les comportements suspects. Ces solutions automatisées réagissent instantanément aux menaces détectées en bloquant le trafic malveillant et en alertant les équipes habilitées. L'intégration avec des bases de données de signatures permet une protection contre les menaces émergentes et les variantes d'attaques connues.
Optimiser les performances réseau
L'analyse de l'utilisation passante identifie les goulots d'étranglement et les périodes de congestion qui impactent l'expérience utilisateur. Cette visibilité guide les décisions d'upgrade et de répartition de charge pour maintenir des performances optimales. La modélisation de la capacité anticipe les besoins futurs et optimise les investissements en infrastructure réseau.
La priorisation du trafic (QoS) garantit la bande passante nécessaire aux applications critiques en attribuant des priorités différenciées selon l'importance métier. Cette gestion intelligente préserve les performances des services essentiels même en période de forte charge. Les politiques de QoS s'adaptent dynamiquement aux conditions réseau pour maintenir les niveaux de service contractuels.
L'optimisation des routes réseau réduit la latence et améliore la résilience en sélectionnant les chemins les plus efficaces. La redondance des chemins assure la continuité de service en cas de panne d'équipement ou de liaison. Les protocoles de routage dynamique s'adaptent automatiquement aux changements de topologie pour maintenir une connectivité optimale.
La compression des données diminue l'utilisation de la bande passante pour certains types de trafic, optimisant particulièrement les liaisons WAN coûteuses ou limitées. Cette technique améliore les performances des applications distribuées et réduit les coûts de télécommunications. L'équilibrage de charge distribue le trafic entre plusieurs liens pour maximiser l'utilisation des ressources disponibles.
Automatiser la surveillance et les réponses
Les scripts de monitoring automatisent la collecte de métriques et la génération de rapports selon des cycles prédéfinis. Cette approche garantit une surveillance continue sans intervention manuelle et libère les ressources techniques pour des tâches à plus forte valeur ajoutée. L'orchestration des tâches de surveillance optimise l'utilisation des ressources système et évite les conflits entre différents processus de collecte.
Les systèmes de ticketing intègrent la surveillance réseau pour créer automatiquement des incidents avec classification et assignation selon la criticité. Cette intégration accélère la résolution des problèmes détectés en routant immédiatement les alertes vers les équipes compétentes. L'historique des incidents enrichit l'analyse des causes racines et améliore les procédures de résolution.
L'orchestration des réponses automatise les actions correctives pour les incidents récurrents selon des playbooks prédéfinis. Ces procédures automatisées réduisent les temps de résolution et standardisent les interventions pour garantir leur efficacité. L'apprentissage automatique améliore continuellement les réponses en analysant les résultats des actions entreprises.
La corrélation d'événements analyse les logs multiples pour identifier les incidents complexes et les campagnes d'attaque sophistiquées. Cette analyse globale révèle les attaques multi-vectorielles qui échappent aux systèmes de détection traditionnels. L'intelligence artificielle identifie les patterns complexes dans les événements d'attaque pour anticiper les phases et déclencher les contre-mesures appropriées.

- Les meilleurs antivirus gratuits
- Les meilleurs antispywares
- Les meilleurs antivirus pour Mac
- Les meilleurs antivirus gratuits pour Mac
- Les meilleurs antivirus iPhone gratuits
- Les meilleurs antivirus Android gratuits
Comment bien vous protéger ? Nos autres conseils antivirus :
- Comment protéger sa vie numérique avec un antivirus ?
- Comment se prémunir et se débarrasser d’un ransomware ?
- Comment identifier le ransomware qui bloque mes données ?
- Comment ne plus recevoir de spam ?
- Comment utiliser et activer le contrôle parental de son antivirus ?
- Comment désinstaller un antivirus ?







