

Pour autant les nouvelles puces de la série Value (d'où la lettre V dans le nom de code) devraient constituer, du moins en ce qui concerne le Radeon X1300, une bonne partie des ventes futures d'ATI. Rappelons en effet qu'ATI, tout comme NVIDIA, fait une grosse partie de son chiffre et de ses profits sur les puces d'entrée de gamme. Après avoir examiné en détail les Radeon X1800 XL et XT, il nous fallait donc nous pencher sur leurs variantes, incarnées par les Radeon X1300 et Radeon X1600, afin de faire le point sur leurs architectures respectives, mais aussi sur leurs performances.

Si l'architecture des Radeon X1000 vous était contée....
Pour sa nouvelle gamme et une fois n'est pas coutume, ATI a décidé de décliner la même architecture sur toutes ses puces et ce quelque soit le segment visé. Du coup, le Radeon X1300 offre les mêmes fonctions que le Radeon X1800 et supporte en conséquence DirectX 9.0c et le fameux Shader Model 3.0. Naturellement, des ajustements ont été opérés par ATI pour rendre les déclinaisons du R520 plus attractives et surtout plus abordables tout en favorisant de meilleurs rendements comme nous le verrons un peu plus loin. Sans revenir sur les détails, que nous évoquions lors du test du Radeon X1800, que nous vous conseillons d'ailleurs vivement de relire (en suivant ce lien), il faut savoir qu'avec le R520 la notion de pixel pipeline a quelque peu évolué. ATI a dorénavant recours à un processeur de répartition des tâches, placé en amont des unités de shader, et censé maximiser leur efficacité en répartissant au mieux les processus, ou threads. En vue de minimiser les latences et maximiser l'efficacité du pipeline 3D, ATI fait appel, et c'est nouveau, à des threads dont la première caractéristique est une taille assez réduite. La puce travaille en effet sur des blocs de 16 pixels, taille qui est à rapprocher de celle permise par l'architecture de NVIDIA qui, elle, travaille sur des blocs d'une taille estimée de 1024 pixels. Grâce à cette taille très réduite, les X1000 profitent d'un meilleur parallélisme global dont les effets se ressentiront notamment au niveau des performances des branchements. Petit rappel rapide, un branchement consiste à introduire une condition dans un pixel shader, ce qui constitue l'une des fonctionnalités les plus intéressantes du Shader Model 3.0. Hélas, c'est aussi l'une des plus gourmandes... Grâce à sa nouvelle architecture, en grande partie pensée pour masquer les latences et pour optimiser l'efficacité du moindre cycle d'horloge, les branchements s'avèrent plus rapides sur l'architecture d'ATI, que sur celle de NVIDIA, la taille réduite des threads permettant bien souvent d'éviter de gaspiller des ressources à calculer des branches de pixels qui n'ont pas besoin de l'être.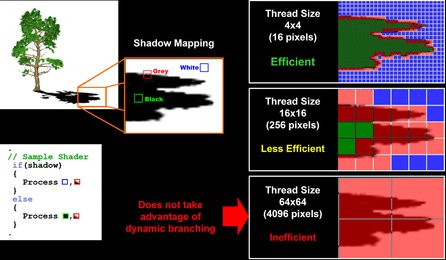
De l'importance de la taille des threads...
Revenons-en aux unités de shader, que l'on appelait autrefois quad, et qui comprennent le nerf de la guerre, à savoir les pixels pipelines. Ces derniers sont toujours au nombre de quatre par unité. Quant aux unités de Vertex si leur nombre a augmenté dans le R520, passant de six à huit, leur agencement a également évolué. ATI les a en effet dotés d'un contrôle de flux dynamique tout en augmentant le nombre de registres et en autorisant un plus grand nombre d'instructions (1024 contre 512). Problème les unités de Vertex Shading ne sont pas de type SIMD : en clair les unités exécutent les mêmes instructions sur tous les vertices (sommets) ce qui peut poser un problème d'efficacité dans le cadre des branchements dynamiques. En outre, et c'est peut être plus gênant, les nouvelles puces Radeon ne gèrent pas le Vertex texturing ou l'accès à une texture depuis un vertex shader. Pourtant, il s'agit de l'une des spécifications de DirectX 9.0c ! ATI ne se plie donc pas tout à fait aux normes édictées par Microsoft et si le vertex texturing est géré par les puces NVIDIA, il convient de relativiser son absence sur les puces ATI. En effet, cette fonction est encore peu utilisée et surtout son coût en terme de performances demeure particulièrement élevé.
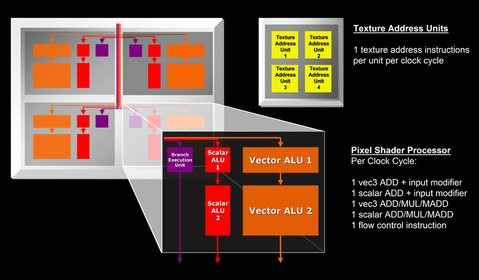
Autopsie d'un Shader Core
Le contrôleur mémoire a également fait l'objet d'un gros travail de la part des ingénieurs d'ATI qui ont doté le R520 d'un contrôleur dit Ring Bus. Issu du processeur Cell d'IBM, ce contrôleur mémoire est censé permettre aux données, du moins schématiquement, de circuler autour de la puce pour être accessibles plus rapidement. Il autorise également une meilleure montée en fréquence tout en utilisant au mieux la bande passante disponible. Pour cela le routage a été simplifié au sein de la puce graphique alors que les données issues d'une puce mémoire peuvent transiter directement vers l'unité du VPU les requérant sans repasser par le contrôleur mémoire.
Question fonctionnalités, l'architecture des R520, RV515 et RV530 offre comme nous le disions précédemment la gestion du Shader Model 3.0. Cela permet notamment aux Radeon X1000 de gérer le fameux HDR sous sa forme la plus avancée. ATI a également travaillé, avec sa nouvelle génération de puces graphiques, sur la qualité graphique ce qui se traduit par l'arrivée d'un nouveau filtrage anisotropique. Celui-ci se repose sur une méthode d'échantillonnage revue. La méthode de compression des textures propre à ATI, et bientôt probablement partie intégrante de la prochaine version de DirectX, évolue quelque peu et le 3DC devient 3DC+. Autre nouveauté, l'anticrénelage est désormais possible lorsque les effets HDR sont utilisés, chose qui n'est pas possible avec les GeForce 6 ou 7. Enfin, la technologie AVIVO, d'accélération et d'optimisation vidéo, est de mise avec les Radeon X1000 tout comme le support du CrossFire. On signalera au passage que le bug de la lecture WMV9 HD présent dans les précédents pilotes CATALYST a été corrigé, quant à l'occupation CPU lors d'un décodage elle s'établit comme suit :
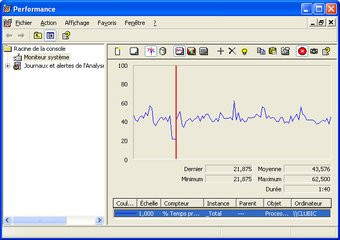
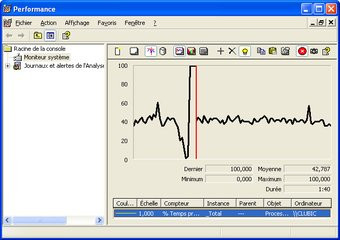
Occupation CPU en décompression WMV9 HD (1080i) : à gauche le Radeon X1300 Pro, à droite le X1600 XT
Radeon X1300 et Radeon X1600 : les spécifications
Le Radeon X1300 profite d'une seule unité de shader, ce qui correspond donc à quatre pixels pipelines et embarque deux unités géométriques (en charge des Vertex). Autre différence vis-à-vis du Radeon X1800 : le nombre d'unités de textures. Alors que le Radeon X1800 comporte seize unités de texture chacune répartie sur quatre blocs, le Radeon X1300 doit se contenter d'un seul bloc soit quatre unités de texture. Les ROPs dont dépendent l'affichage final sont au nombre de quatre ce qui tout bien considéré semble donner au Radeon X1300 un bon équilibre, du moins sur le papier. L'autre grande différence avec le Radeon X1800 provient de la disparition pure et simple du contrôleur mémoire 512 bits dit Ring Bus. Dans un souci d'économie, ATI l'a en effet tout simplement fait passer à la trappe sur le Radeon X1300 au profit d'un simple contrôleur 128 bits.Le Radeon X1600 adopte quant à lui une architecture un tantinet plus musclée. C'est ainsi qu'on a droit à trois unités de Shader, soit douze pixels pipelines, mais seulement quatre unités de texturing. On notera au passage que c'est la première fois qu'un VPU profite d'un découplage des pixels pipelines et des unités de texture. En outre, et c'est une spécificité du Radeon X1600, les trois unités de shaders constituantes du pixel pipelines ne sont pas indépendantes l'une vis-à-vis de l'autre. Cela implique que le Radeon X1600 travaille sur des groupes de pixels plus gros, de l'ordre de 48 pixels. Aux trois unités de shaders du X1600 s'ajoutent cinq unités géométriques en charge du traitement des vertex shader et quatre ROPs. En ce qui concerne le contrôleur mémoire, ATI propose ici son Ring Bus en 4 x 32 bits, qui correspond plus ou moins à un bus mémoire de deux voies sur 128 bits chacune.
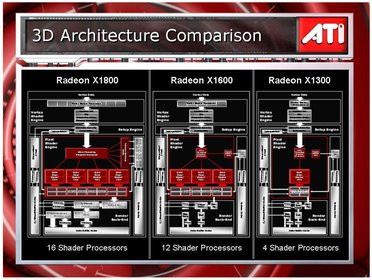
Comparaison architecture ATI R520, RV530 et RV515
Comparativement, le Radeon X700, ancienne puce milieu de gamme d'ATI, embarquait seulement huit pixels pipelines mais huit unités de texture et six unités géométriques. Cette rapide mise en perspective du Radeon X1600 face à son prédécesseur soulève une interrogation en augmentant le nombre de pipelines tout en diminuant le nombre d'unités géométriques et de texture, ATI peut-il proposer de meilleures performances ? C'est ce que nous verrons.
Radeon X1300, X1600 : les puces
Après avoir évoqué l'architecture des Radeon X1300 et X1600, il nous faut revenir sur les caractéristiques physiques des puces. Les RV515 (Radeon X1300) et RV530 (Radeon X1600) sont tous deux gravés en 90nm par TSMC. Alors que le Radeon X1300 comporte près de 100 millions de transistors, on en dénombre pas loin de 160 millions chez son grand frère, le Radeon X1600. Cette différence du nombre de transistors à un impact direct sur la surface du die qui passe d'un peu moins de 100 mm² pour le X1300 à plus de 150 mm² pour le X1600.En ce qui concerne les fréquences de fonctionnement, ATI cadence la version PRO du VPU X1300 à 600 MHz et la mémoire qui l'accompagne à 400 MHz. Pour la mouture XT du Radeon X1600 on dispose d'un VPU opérant à 590 MHz et d'une mémoire cadencée à 690 MHz. Notez au passage qu'ATI limite le mode anticrénelage à un maximum de 6x sur le Radeon X1300 Pro. Sachez enfin que le fabricant décline ses nouveaux Radeon X1300 et X1600 dans des versions encore plus édulcorées dont les spécifications figurent dans le tableau ci-dessous :
| Radeon X1300 HyperMemory | Radeon X1300 | Radeon X1300 Pro | Radeon X1600 Pro | Radeon X1600 XT | |
| Interface | PCI-Express 16x | PCI-Express 16x | PCI-Express 16x | PCI-Express 16x | PCI-Express 16x |
| Gravure | 0,09 µ | 0,09 µ | 0,09 µ | 0,09 µ | 0,09 µ |
| Transistors | 100 millions | 100 millions | 100 millions | 157 millions | 157 millions |
| RAMDAC | 2 x 400 MHz | 2 x 400 MHz | 2 x 400 MHz | 2 x 400 MHz | 2 x 400 MHz |
| T&L | DirectX 9.0c | DirectX 9.0c | DirectX 9.0c | DirectX 9.0c | DirectX 9.0c |
| Pixels Pipelines | 4 | 4 | 4 | 12 | 12 |
| Vertex Pipelines | 2 | 2 | 2 | 5 | 5 |
| Mémoire embarquée | 32 Mo (128 Mo partagée) | 128 ou 256 Mo | 256 Mo | 128 ou 256 Mo | 128 ou 256 Mo |
| Interface mémoire | 64 bits | 128 bits | 128 bits | 2 x 128 bits | 2 x 128 bits |
| Bande passante mémoire | 8,1 Go/s | 12,8 Go/s | 12,1 Go/s | 22,1 Go/s | |
| Fréquence GPU | 450 MHz | 450 MHz | 600 MHz | 500 MHz | 590 MHz |
| Fréquence mémoire | 1 GHz | 500 MHz | 800 MHz | 780 MHz | 1,38 GHz |
Les cartes Radeon X1300 / X1600
Pour ce test ATI nous a fait parvenir des cartes de référence équipées l'une du Radeon X1300 Pro, l'autre du Radeon X1600 XT. Physiquement les deux cartes sont pour ainsi dire très proches, le PCB étant grosso modo identique. De couleur rouge et au format PCI-Express, les cartes sont de type simple-slot et ne nécessitent aucun raccordement électrique. Le système de refroidissement employé par ATI est constitué d'une base cuivre recouvrant le VPU, et surmontée d'un radiateur, lui-même complété par un ventilateur façon turbine. La description est suffisamment éloquente pour comprendre que l'ensemble est particulièrement bruyant, hélas du même acabit que feu le Radeon X700 XT. On ne pourra donc qu'espérer que les partenaires d'ATI emploieront un ventirad différent pour une plus grande discrétion.

Carte ATI Radeon X1600 XT
Le Radeon X1300 Pro que nous avons reçu était accompagné de 256 Mo de mémoire DDR2 répartis sur des puces Infineon à 2,5ns. Pour sa part le Radeon X1600 XT embarque lui aussi 256 Mo de mémoire GDDR3 et ATI utilise ici des composants Samsung. En sortie le X1600 XT est muni de deux connecteurs DVI quand le Radeon X1300 Pro a droit à un connecteur VGA et une prise DVI. Enfin, les deux cartes profitent d'une sortie TV. Les deux cartes voient leur PCB muni d'un emplacement pour une puce Rage Theater en charge des entrées/sorties vidéo, mais ATI a choisi de ne pas en doter ses cartes de référence.


Carte ATI Radeon X1300 Pro
Un mot sur l'overclocking

- Carte mère Gigabyte GA-K8N SLI (BIOS F4),
- Processeur AMD Athlon 64 3800+,
- 2x512 Mo Corsair TwinX PC3200 XL,
- Disque dur Western Digital Raptor 36 Go Serial-ATA 150
Aquamark 3
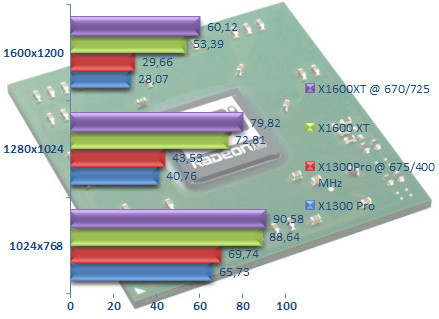
On démarre notre test avec AquaMark 3. Ici on notera tout d'abord que les GeForce 6200 et Radeon X550 sont à égalité presque parfaite, quelque soit la résolution, tandis que le Radeon X1300 Pro fait mieux et pas qu'un peu. La dernière puce d'ATI affiche ici des performances 50 % supérieures au Radeon X550 ce qui met notre X1300 Pro au niveau du GeForce 6600. Le Radeon X1600 XT affiche quant à lui des performances plutôt décevantes puisqu'il ne serait que 4 % plus rapide que le Radeon X700 Pro, pas de quoi fanfaronner. Du coup les Radeon X800 GTO et autres GeForce 6600 GT et 6800 GS sont loin devant. Les amateurs de chiffre retiendront que le GeForce 6600 GT est 13 % plus véloce que le Radeon X1600 XT en 1600x1200.
Unreal Tournament 2003
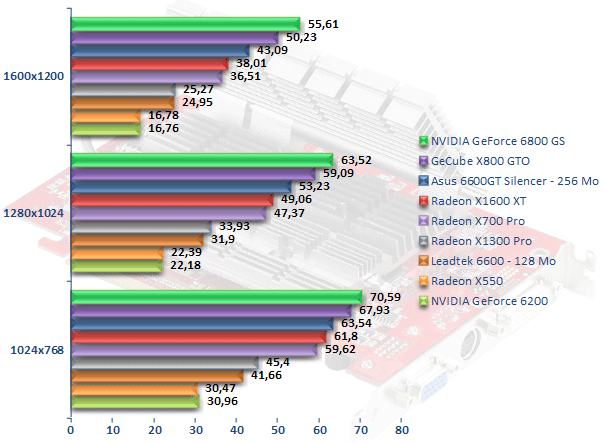
On poursuit nos tests avec Unreal Tournament 2003. Là encore, Radeon X550 et GeForce 6200 sont à égalité. Le Radeon X1300 Pro s'affiche comme plus rapide que le GeForce 6600 dans les résolutions courantes (1024x768 et 1280x1024) alors que les deux puces sont quasiment à égalité en 1600x1200. Le Radoen X1600 XT affiche ici des performances 16 % supérieures au Radeon X700 Pro, ce qui est toujours bon à prendre, mais ne le place hélas toujours pas devant le GeForce 6600 GT de NVIDIA. La dernière puce milieu de gamme d'ATI reste d'ailleurs assez loin du X800 GTO ou du GeForce 6800 GS qui demeurent jusqu'à 56 % plus performantes.
3DMark 05
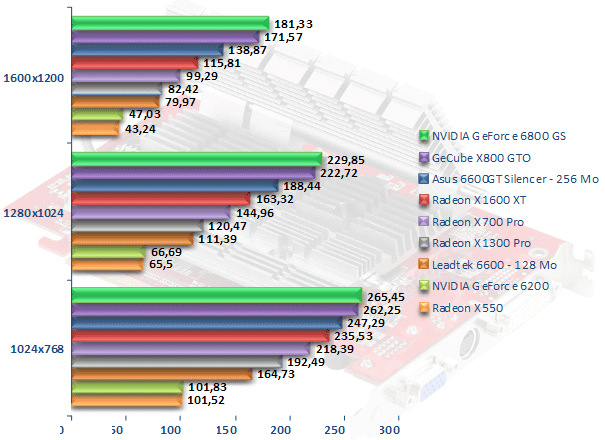
Enchaînons avec 3DMark 05. Ici, et c'est de prime abord assez surprenant, le Radeon X1600 XT est en tête, tout simplement avec des performances presque identiques au GeForce 6800 GS de NVIDIA. Face au Radeon X700 Pro, le Radeon X1600 XT est 67 % plus rapide. En ce qui concerne les puces graphiques d'entrée de gamme, le Radeon X1300 Pro conserve ici un net avantage sur le Radeon X550 de l'ordre de 82 %. Face au GeForce 6200, le gain atteint tout de même 91 % !
Far Cry v1.33
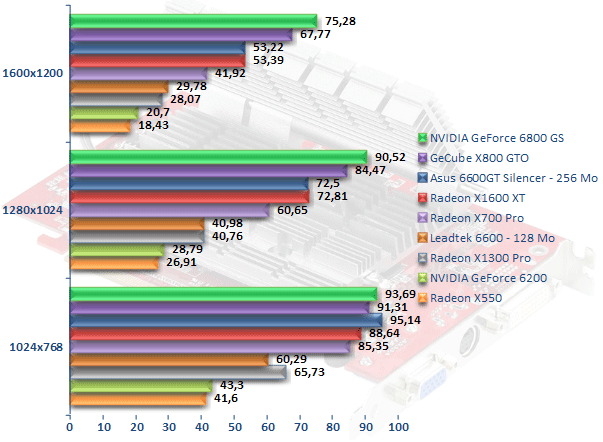
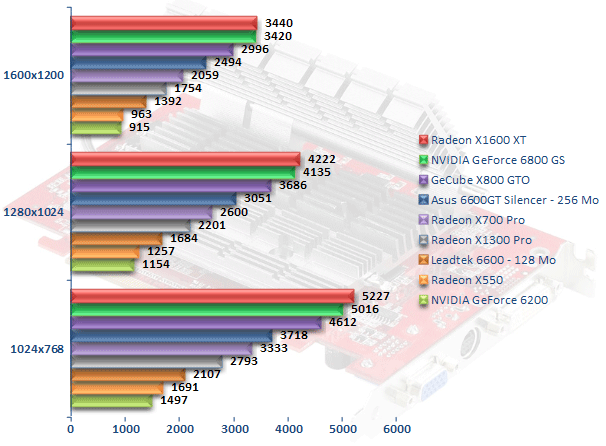
L'ami Jack Carver, le héros du jeu Far Cry, donne un avantage certain au Radeon X1300 Pro sur ses concurrents les Radeon X550 et GeForce 6200 que l'on a toujours beaucoup de mal à départager. Ici, le Radeon X1300 Pro peut se montrer jusqu'à 50 % plus rapide que le X550. Cela ne suffit toutefois pas à afficher de meilleures performances que le GeForce 6600, les deux cartes restant au coude à coude. Le Radeon X1600 XT affiche quant à lui des performances convaincantes de 27 % supérieures à celles de son prédécesseur le Radeon X700 Pro. Cela permet au Radeon X1600 XT de faire aussi bien que le GeForce 6600 GT, mais hélas pas mieux. Du coup les X800 GTO et le très récent GeForce 6800 GS sont en tête.
Far Cry v1.33 - FSAA 4x & Aniso 8x
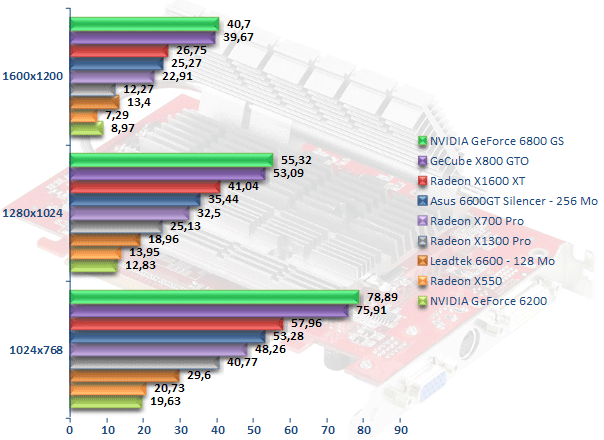
Poursuivons nos aventures sous Far Cry, mais cette fois-ci en faisant usage des fonctions de filtrage. On retrouve en tête le GeForce 6800 GS et le Radeon X800 GT dont l'avantage sur le Radeon X1600 XT est tout de même conséquent. Le Radeon X1600 XT s'avère 6 % plus rapide que le GeForce 6600 GT en 1600x1200 ce qui ne constitue pas vraiment un avantage décisif. En revanche, face au Radeon X700 Pro, le gain atteint les 16 %. En ce qui concerne les puces entrée de gamme, notre duo X550 et GeForce 6200 est toujours aussi proche, ce qui permet au X1300 Pro de prendre le large tout en offrant des performances supérieures au GeForce 6600, sauf il est vrai en 1600x1200.
Half-Life 2
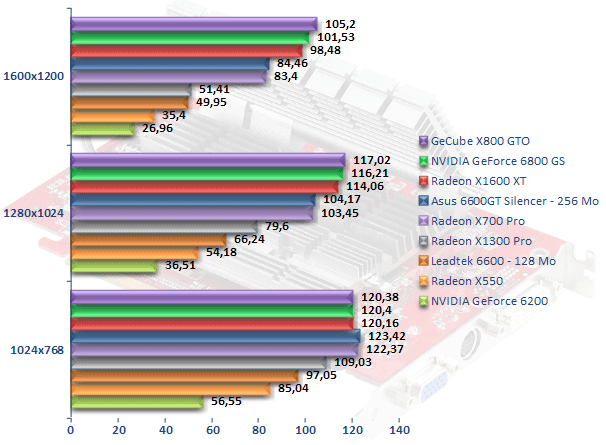
Longtemps attendu, ardemment désiré par certains, Half-Life 2 est finalement sorti, et ce, avant Duke-Nukem Forever ! Nous nous penchons donc sur le comportement de nos cartes avec ce titre vedette tout récemment adapté à la XBox. Le moteur du jeu est limité par le CPU et du coup les résultats obtenus en 1024x768 ne sont pas très probants. Il faut monter en résolution pour obtenir une véritable hiérarchie entre nos diverses cartes. On commence par l'entrée de gamme où, une fois n'est pas coutume, le Radeon X550 fait mieux que le GeForce 6200 et pas qu'un peu ! Le tout nouveau Radeon X1300 Pro s'octroye des performances supérieures à ses concurrents d'entrée de gamme et fait mieux que le GeForce 6600. En 1280x1024, nous avons un Radeon X1300 Pro qui est 20 % plus rapide que le GeForce 6600. Ce comportement se retrouve avec le Radeon X1600 XT qui arroche le GeForce 6800 GS et fait mieux, de l'ordre de 16 %, que le GeForce 6600 GT. Ce dernier était d'ailleurs à égalité avec le Radeon X700 Pro.
Doom 3
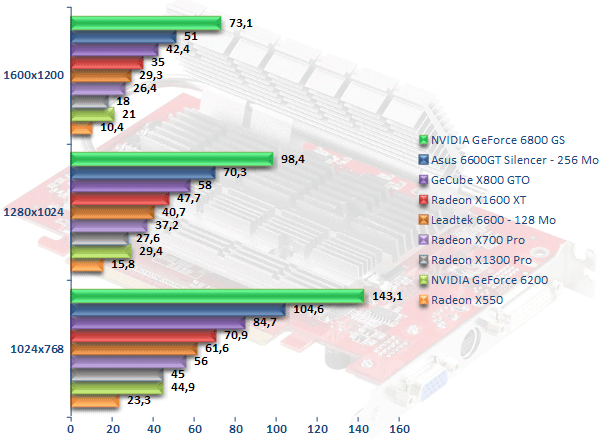
Doom 3, malgré son gameplay critiqué et critiquable, reste un très bon moteur graphique, OpenGL de surcroît. En revanche il a cette fâcheuse tendance à favoriser les Cartes Graphiques NVIDIA. Du coup on retrouve en pôle position le GeForce 6800 GS, suivi du GeForce 6600 GT d'Asus. Le Radeon X1600 XT se hisse tout juste devant le GeForce 6600 et affiche un gain de performances de quelque 28 % sur le Radeon X700 Pro. Sur l'entrée de gamme et alors que jusqu'à maintenant le Radeon X1300 Pro balayait le GeForce 6200, ce dernier fait mieux, de peu il est vrai, que la dernière puce d'ATI. Comparativement le Radeon X1300 Pro est 74 % plus rapide que le X550 en 1280x1024 reste que le framerate est trop léger pour jouer dans de bonnes conditions sans faire de concessions sur la qualité graphique.
Splinter Cell : Chaos Theory
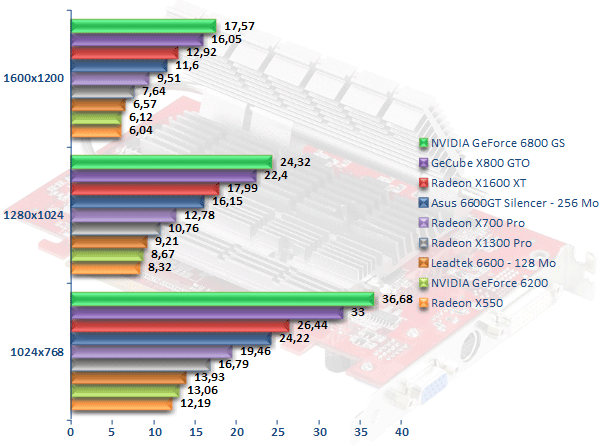
Notre espion au grand coeur (NDLA : je sais, c'est stupide, mais ça sonne bien), Sam Fisher, a le don dans l'épisode « Chaos Theory » d'éprouver particulièrement les cartes graphiques. Le GeForce 6800 GS caracole ici en tête, suivi du Radeon X800 GTO. Le Radeon X1600 XT fait sensiblement mieux que le GeForce 6600 GT avec un écart atteignant 11 % en 1600x1200. Alors que le Radeon X700 Pro travaille en Shader Model 2.0, le Radeon X1600 XT opère avec un rendu Shader Model 3.0 ce qui ne l'empêche pas d'être 36 % plus rapide, toujours en 1600x1200. Du côté de l'entrée de gamme, Radeon X550 et GeForce 6200 sont encore une fois à égalité et si le GeForce 6600 peine à faire mieux, le Radeon X1300 Pro devance l'ensemble des cartes que nous venons juste de citer.
Battlefield 2
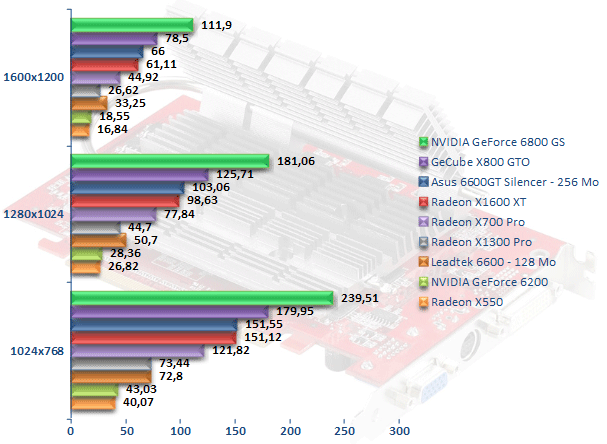
Sous Battlefield 2, le GeForce 6800 GS affiche une sérieuse avance sur ses concurrents les plus directs ce qui le place en tête, sans trop de difficulté. Le Radeon X1600 XT affiche ici des performances quasiment identiques au GeForce 6600 GT, ce qui rend de fait le Radeon X800 GTO plus puissant avec des performances 28 % plus importantes. Sur l'entrée de gamme, le Radeon X1300 Pro est à la peine et fait moins bien que le GeForce 6600. Ce dernier dispose généralement d'un avantage de 13 %. En revanche le Radeon X1300 Pro se comporte plutôt bien face au X550 grâce à des performances 66 % supérieures.
F.E.A.R.
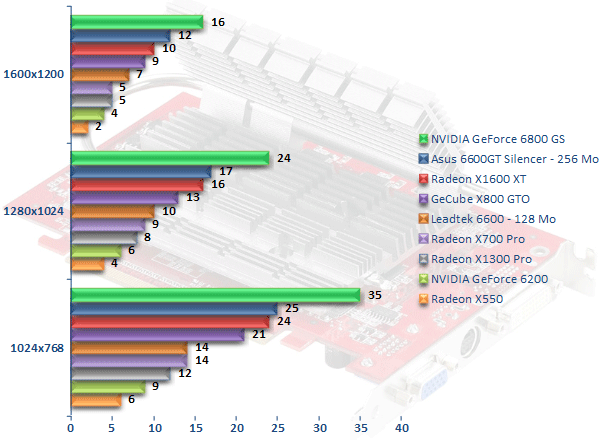
Dernier FPS à la mode, F.E.A.R. est à l'instar de Splinter Cell : Chaos Theory particulièrement gourmand. Affectées par un bug qui sera prochainement corrigé, les cartes ATI voient leurs performances quelque peu amoindries. Ceci laisse le champ libre à NVIDIA qui place deux de ces cartes sur les premières marches du podium. Reste que le GeForce 6600 GT n'a qu'un avantage modéré sur le Radeon X1600 XT (6 %) qui parvient à faire mieux que le Radeon X800 GTO. Plus rapide le GeForce 6600 affiche un avantage certain sur le Radeon X1300 Pro. Ce dernier fait toutefois mieux que le Radeon X550 mais passer de 4 à 8 fps ne permet toujours pas de jouer convenablement, dommage !
Quake 4
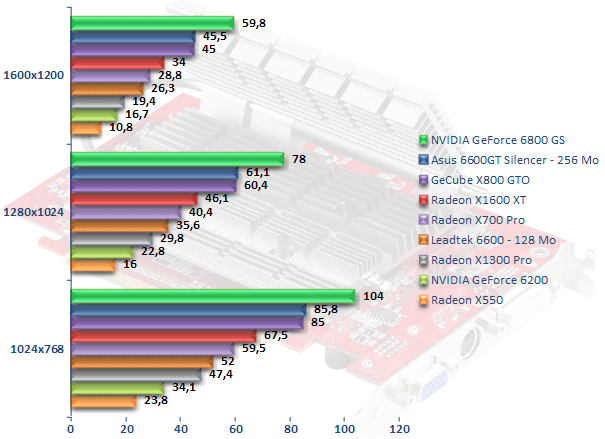
On referme ce test par Quake 4, le tout dernier opus d'une des références du genre. Le GeForce 6800 GS conserve la pole position, alors que le GeForce 6600 GT fait jeu égal avec le Radeon X800 GTO. GeForce 6600 GT et Radeon X800 GTO font une fois encore mieux que le Radeon X1600 XT. La nouvelle puce milieu de gamme d'ATI est tout de même 14 % plus rapide que le Radeon X700 Pro. Côté entrée de gamme nous avons un Radeon X1300 Pro qui bien que significativement plus rapide que le Radeon X550 n'égale pas le GeForce 6600.
Conclusion
À l'heure de refermer ce test, force est de reconnaître que les nouvelles puces Radeon X1300 et X1600 sont loin de transfigurer le segment du marché auquel elles se destinent. Fort de cet amer constat, il appartient cependant de bien distinguer le Radeon X1300 Pro du Radeon X1600 XT. Le Radeon X1300 Pro, qui représente en quelque sorte le haut de l'entrée de gamme nouvelle formule d'ATI, est plutôt une bonne solution. Globalement la puce offre en effet des performances bien supérieures à ses prédécesseurs alors que, selon les tests, elle fait jeu égal avec le GeForce 6600 aujourd'hui proposé dans la même gamme de prix. Plutôt convaincant, le RV515 est tout de même loin de susciter chez nous un enthousiasme démesuré, et ce, pour plusieurs raisons. Tout d'abord, la version Pro que nous avons pu tester risque d'être bien vite éclipsée par les modèles standard et HyperMemory aux performances moindres. Ensuite, passer de 6 à 12 FPS sous F.E.A.R. représente certes un doublement des performances, mais qui reste hélas inutile : à ce framerate le jeu est inexploitable en 1024x768, toutes options activées. Enfin, et ce sera notre dernière critique, le prix du Radeon X1300 Pro est élevé : pas moins de 100 euros pour les versions les moins onéreuses.Si le Radeon X1300 Pro se sort bon an mal an plutôt bien de l'épreuve du feu, le nouveau Radeon X1600 XT laisse une impression nettement plus mitigée. La puce délivre en effet des résultats peu homogènes qui font parfois pâle figure face à un GeForce 6600 GT vieux de plus d'un an, ou pire à un Radeon X800 GTO ! Les 12 pixels pipelines du Radeon X1600 XT font bien sur le papier, mais en pratique ils sont pénalisés par le nombre restreint d'unités de texture, et dans une moindre mesure par la quantité limitée de vertex pipelines, qui ne sont pas toujours d'un grand secours pour épauler le Radeon X1600 XT. Peu équilibrée, la puce compense ses faiblesses par des fréquences de fonctionnement élevées et par l'utilisation d'une mémoire rapide, donc forcément onéreuse. Et c'est justement là que rien ne va plus... Un cran au-dessus du Radeon X700 Pro, mais inférieur au GeForce 6600 GT, le Radeon X1600 XT devait faire ses premiers pas autour des 249 euros. Autant dire qu'à ce tarif la puce n'avait aucune chance. Son prix, a donc été revu à la baisse, et s'établit dorénavant entre 179 et 199 euros. Mais malgré l'effort consenti, la nouvelle puce d'ATI se fait cannibaliser par sa propre famille, puisque le Radeon X800 GTO que l'on trouve au même tarif est nettement plus rapide ! Certes ce dernier se contente du Shader Model 2.0, aujourd'hui un brin désuet, mais l'efficacité est au rendez-vous. Du coup et fort de ces considérations tarifaires, le GeForce 6600 GT de NVIDIA reste probablement le meilleur choix avec un prix qui, tournant autour des 150 euros, est définitivement plus attractif que celui d'ATI.
